Appetite for Noise : j'ai testé le récit Ozempic sur les données nationales
Le PDG de Walmart, Morgan Stanley et une série de notes d'analystes affirment que les GLP-1 font déjà plier les dépenses américaines en restaurants, alcool et épicerie. Le test naïf avant/après sur les données FRED donne une réponse confiante, significative, et fausse en direction. Voici ce qui survit à une inférence correcte et à un vrai contrôle de tendance, et la vraie taille de l'effet.
Environ un adulte américain sur huit prend maintenant un GLP-1. Le PDG de Walmart, Morgan Stanley et une série de notes d'analystes affirment qu'Ozempic et ses cousins font déjà plier les dépenses des consommateurs en restaurants, alcool et collations. La question que je voulais trancher est petite mais irritante : est-ce qu'on le voit vraiment dans l'agrégat national, ou est-ce que le récit court devant les données ?
Pourquoi je l'ai construit
Zach O'Hagan chez Zerve a proposé l'angle : « effets de second ordre des GLP-1 sur l'économie, avec des proxys de données carte de crédit, le trafic en restaurant, les ventes d'alcool et les dépenses liées à l'obésité, quantifier les déplacements attribuables à l'adoption d'Ozempic. » Même squelette que mon précédent projet Zerve (Polymarket Decoded) : prendre un récit de marché, le tester sur des données primaires, nommer l'écart, assumer les limites.
Les panels carte de crédit réels (Affinity, Earnest, Consumer Edge) sont payants. Les agrégats mensuels FRED (commerce de détail et restauration) sont la version publique des mêmes dépenses sous-jacentes : même forme, moins de granularité. Je le dis clairement plutôt que de le cacher.
Ce que dit le test évident
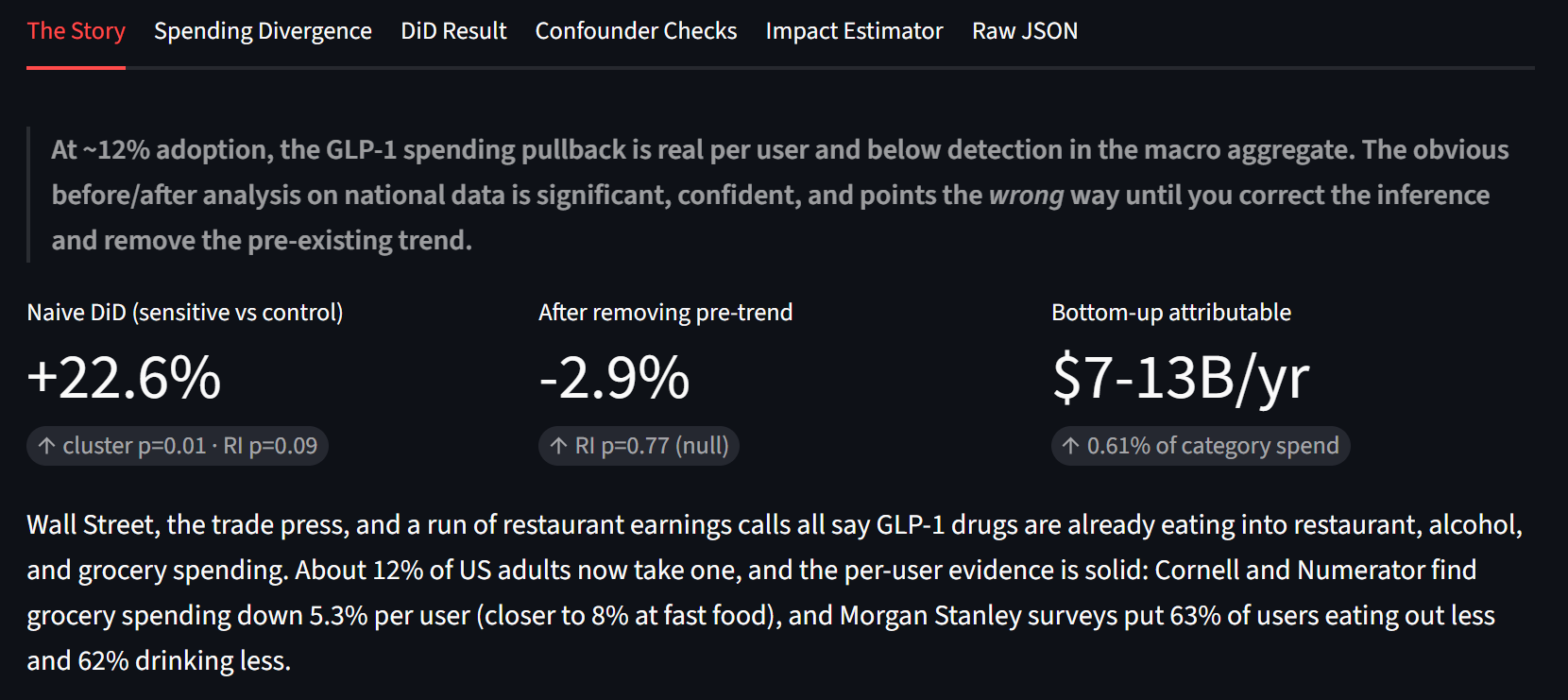
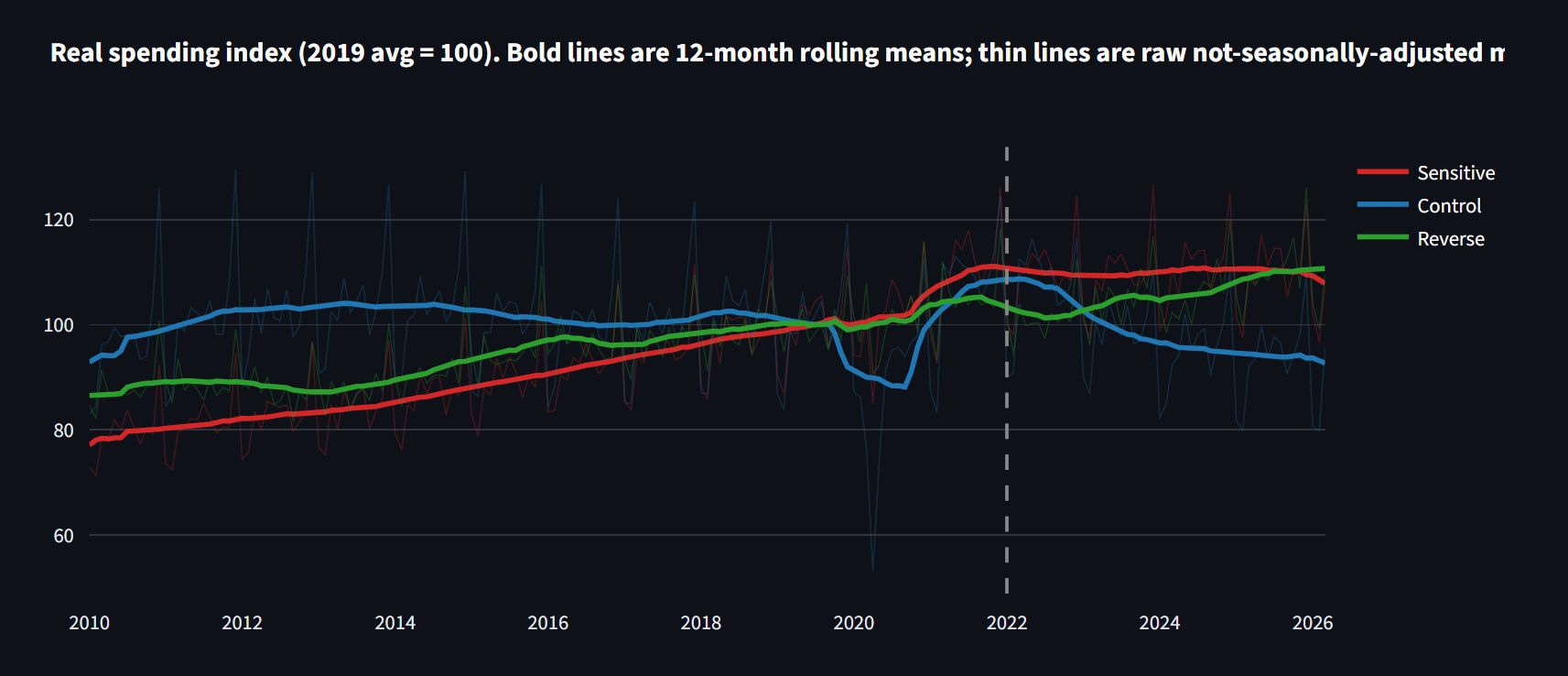
Groupe traité : restaurants, magasins de bière/vin/alcool, magasins d'alimentation. Groupe témoin : essence, vêtements, meubles, électronique, matériaux de construction. Différence-de-différences avant et après la rampe GLP-1 de 2022, sur des dépenses ajustées de l'inflation (chaque catégorie déflatée par son propre IPC, indexée à 2019 = 100).
La réponse de manuel est significative : +22,6 %, p cluster-t = 0,010, IC 95 % [+5,0, +43,2]. Mais regardez le signe. Les catégories sensibles aux GLP-1 ont crû plus vite que les témoins, pas moins vite. Si on s'arrêtait là, on écrirait « les GLP-1 n'ont aucun effet, les restaurants explosent ». Ce titre serait également faux.
Pourquoi ce chiffre trompe sur deux fronts
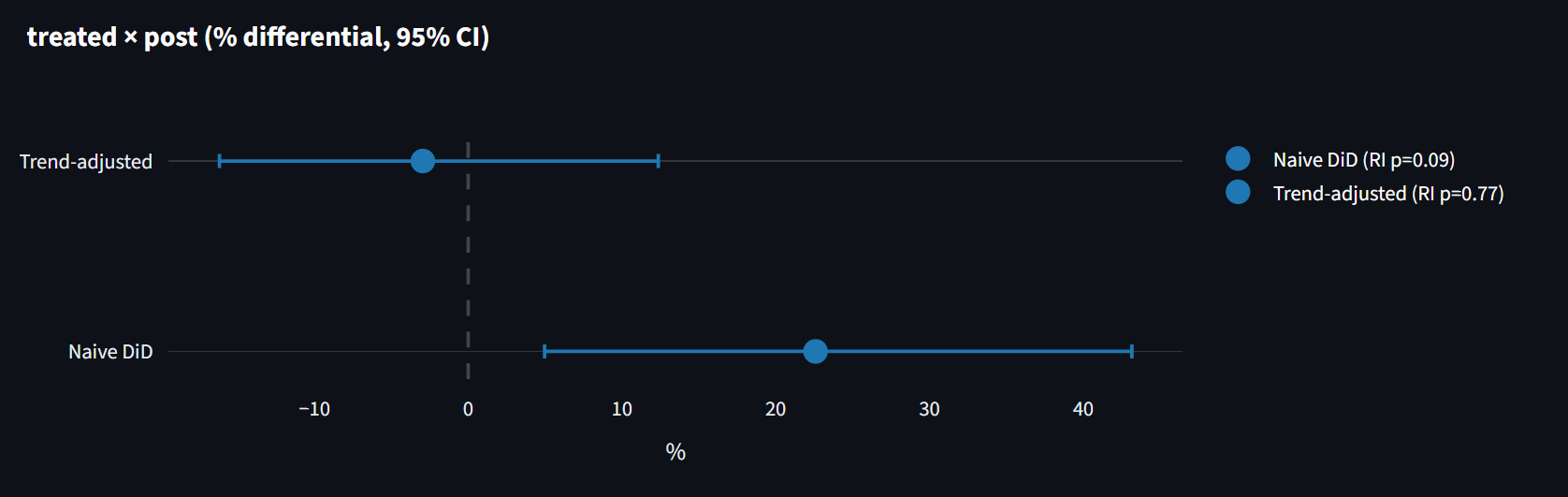
L'inférence d'abord. Avec seulement trois catégories traitées, les erreurs cluster-robustes sont connues pour sur-rejeter fortement (Conley-Taber 2011, MacKinnon-Webb). Plutôt que de me fier à la formule, j'ai permuté l'étiquette « traitée » sur les 56 façons de choisir 3 des 8 catégories et classé l'estimation réelle contre cette distribution. Le p honnête par inférence de randomisation est 0,089, pas 0,010. Non significatif à 5 %.
L'identification ensuite. J'ai relancé le même modèle avec une fausse date de traitement en 2018, avant que ces médicaments comptent et avant la COVID. Si le design était propre, le placebo serait à zéro. Il revient à +13,9 %, le même écart, des années avant que les GLP-1 existent.
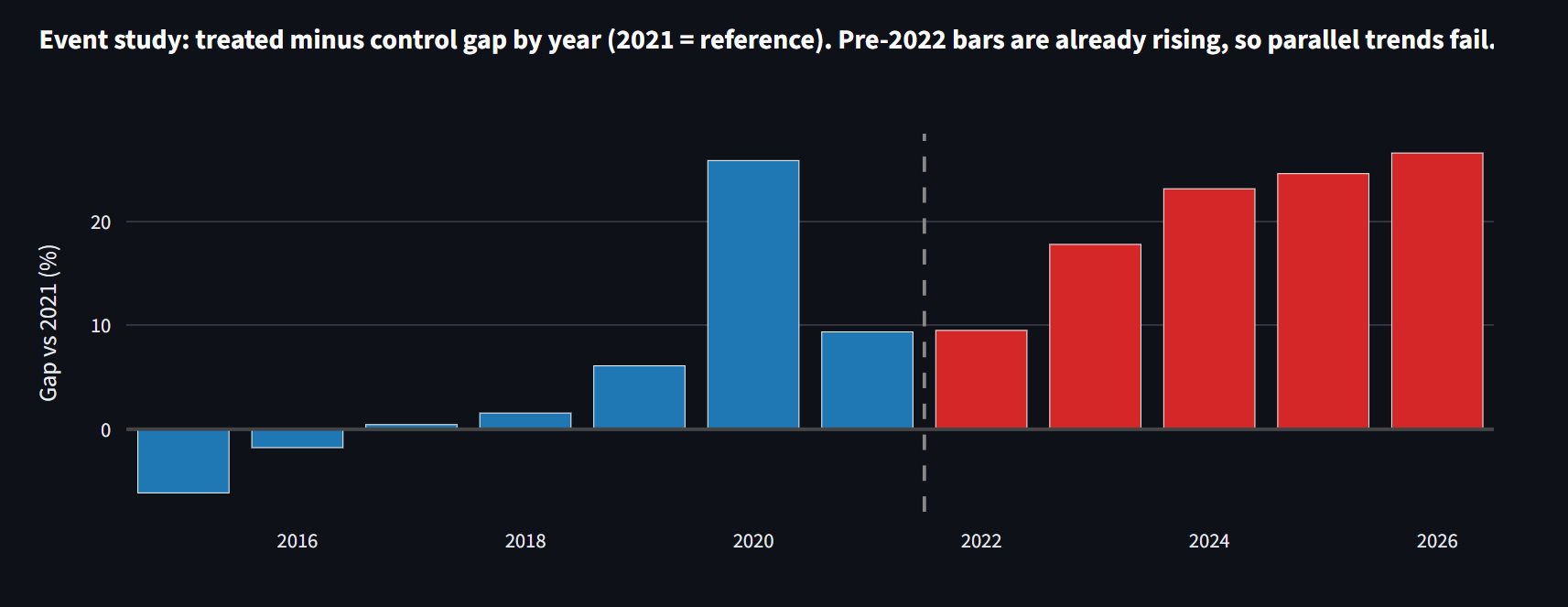
Un test F joint formel sur ces tendances pré-2022 rejette l'hypothèse de tendances parallèles, sur laquelle toute la méthode repose, à F = 80, p < 0,0001. Le cadrage suit Rambachan et Roth (2023) : plutôt que de supposer que les tendances parallèles tiennent, je montre qu'elles ne tiennent manifestement pas, et je rapporte ce qui reste une fois la tendance retirée.
La réponse honnête, en trois angles
- DiD ajustée pour la tendance (chaque groupe avec sa propre tendance) : -2,9 %, IC 95 % [-16,2, +12,4], p RI = 0,77. Statistiquement nulle.
- Dose-réponse (courbe d'adoption continue du bloc 2 comme traitement au lieu d'une indicatrice post) : -2,2 % par écart-type d'adoption, p = 0,31. L'écart cesse de suivre l'adoption dès qu'on retire la tendance.
- Robustesse : fenêtre hors-COVID, pré-période propre 2015-2019, restaurants + alcool seuls, retrait de l'essence à prix volatil, balayage de coupure 2021-06 à 2023-01. La nullité survit à toutes les variantes.
Traduire en dollars sans truquer la précision
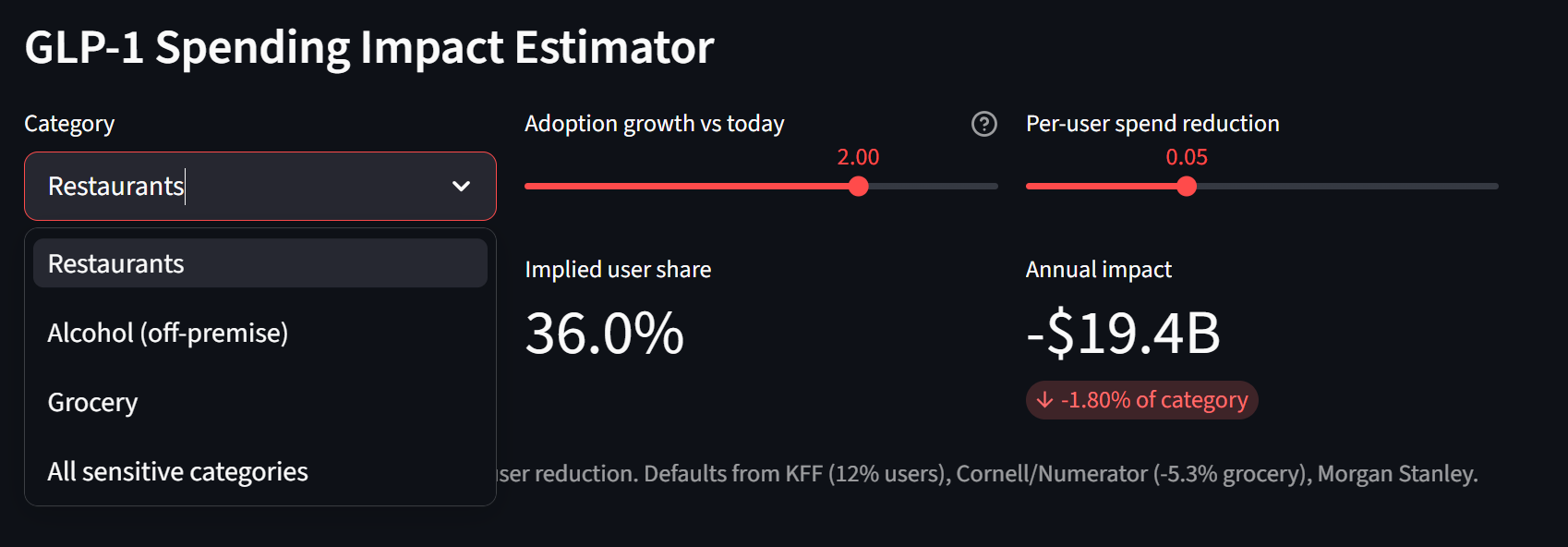
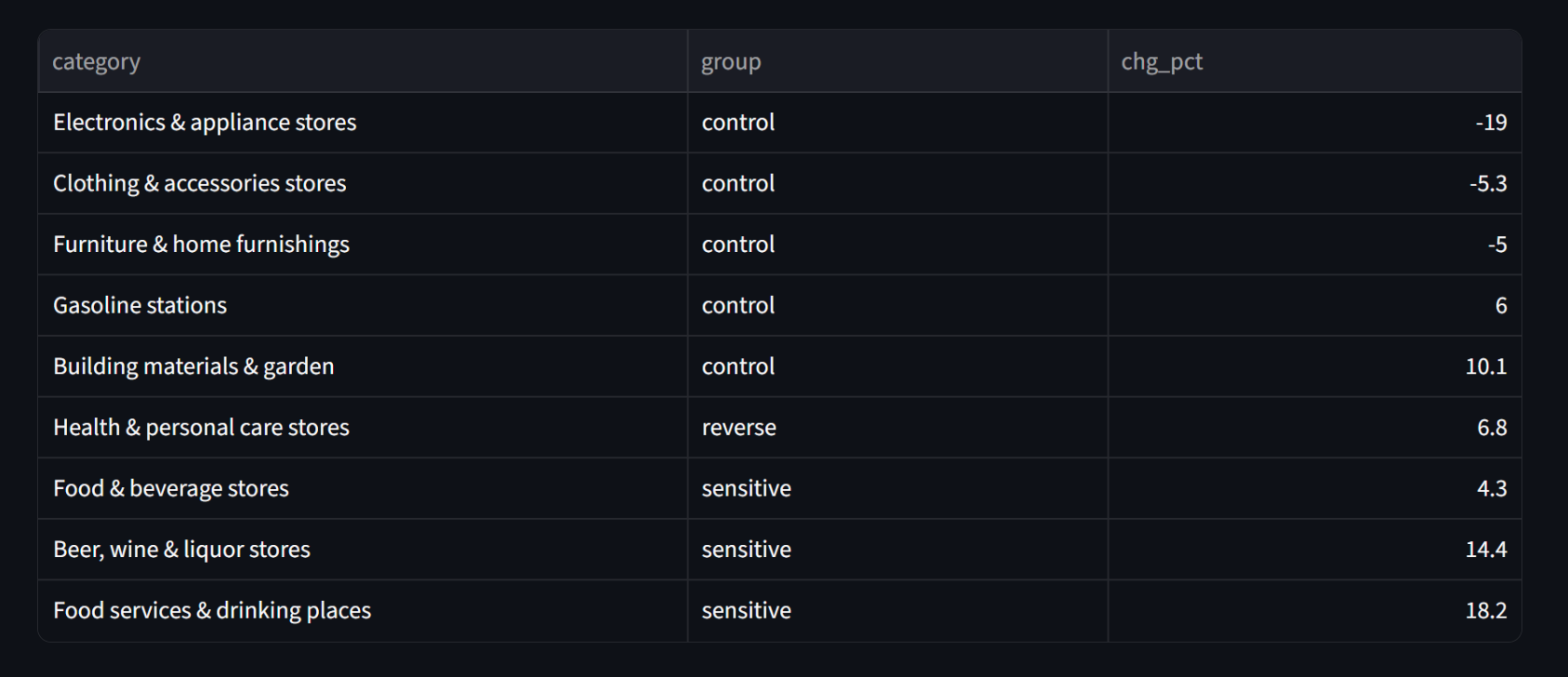
L'effet par utilisateur est réel et documenté : Cornell/Numerator trouvent une baisse de 5,3 % en épicerie par utilisateur GLP-1 sur six mois, -8 % en restauration rapide, -11 % en collations salées, plus fort pour les ménages aisés. À environ 12 % d'adoption adulte sur les 2,16 billions $ que les Américains dépensent dans ces catégories (1 075 G$ en restaurants, 1 017 G$ en épicerie, 71 G$ en magasins d'alcool), l'arithmétique bottom-up arrive à environ 7 à 13 G$ par année, soit 0,3 à 0,6 % de la catégorie.
La fourchette est honnête quant aux restaurants. Les données transactionnelles de Numerator et Circana montrent que les utilisateurs GLP-1 dépensent en fait plus en restaurants pleins services pendant que la restauration rapide et l'épicerie baissent, donc une prédiction agrégée « les restaurants baissent » n'est même pas propre au niveau micro. Le plancher ne crédite aucune baisse en restaurants, le plafond crédite le chiffre du sondage Morgan Stanley. Dans les deux cas, c'est une erreur d'arrondi face au virage séculaire vers les services et à la reprise post-COVID qui dominent l'agrégat.
Comment je l'ai construit
Dix blocs Python dans un canvas Zerve, chaînés via des dataframes pandas. Le bloc 1 récupère les ventes au détail/restauration mensuelles FRED et les séries IPC BLS depuis 2010 avec une Secret Constant pour la clé FRED. Le bloc 2 construit un indice d'adoption GLP-1 ancré sur les approbations FDA (Ozempic 2017, Wegovy 2021, Mounjaro 2022, Zepbound 2023) et la trajectoire documentée des ordonnances (0,3 M/mois à 3,5 M/mois, 2017 à 2024), tente Google Trends via pytrends, et bascule sur une série calibrée intégrée pour que les apps déployées ne dépendent jamais d'un endpoint instable.
Les blocs 3 à 5 sont la colonne vertébrale analytique : déflation par IPC spécifique (restaurants par food-away-from-home, alcool par alcoholic-beverages, épicerie par food-at-home, témoins par IPC global), agrégation par catégorie, puis la DiD elle-même en statsmodels avec erreurs cluster-robustes ET une boucle manuelle d'inférence par randomisation sur les 56 étiquetages. Le bloc 5 fait aussi tourner la dose-réponse pour que la courbe d'adoption du bloc 2 alimente l'inférence, pas juste le récit.
Le bloc 6 est celui de l'honnêteté brutale : fenêtres hors-COVID, placebo, balayage de coupure, étude d'événement avec test F joint sur les pré-tendances, retrait de l'essence, redéflation. Le bloc 7 attribue le chiffre en dollars bottom-up. Les blocs 8 à 10 sont des visuels Plotly, un service FastAPI et un tableau de bord Streamlit. Les deux déploiements utilisent l'endpoint CSV sans clé de FRED, donc les apps en ligne n'ont besoin d'aucun secret.
Ce qui a été difficile
Le piège était le très petit nombre de clusters traités. Trois catégories semble correct jusqu'à ce qu'on se rappelle que les t-stats cluster-robustes ont besoin de beaucoup de groupes pour bien se comporter. Le correctif (inférence par randomisation sur les 56 étiquetages) est la solution de manuel pour exactement ce cas, mais le résultat est inconfortable : le chiffre principal passe de p = 0,01 à p = 0,09. Il faut accepter de publier ça.
L'autre piège était de traiter les tendances parallèles comme une case à cocher. La plupart des écrits DiD énoncent l'hypothèse et passent à autre chose. Ici elle échoue de manière visible. La bonne décision était de mener avec le test de pré-tendance et de traiter la spécification ajustée pour la tendance comme la défendable, pas d'enterrer l'échec en annexe. Le cadrage Rambachan-Roth m'a aidé à articuler ça.
Petite douleur en plus : l'écart d'IPC d'octobre 2025 causé par le shutdown BLS est interpolé au bloc 3, la ligne des services alimentaires (NAICS 7225) mélange pleins services et restauration rapide (exactement la séparation où l'évidence micro diverge), et les ventes en magasins d'alcool manquent complètement l'alcool sur place. L'agrégat ne peut pas isoler les sous-catégories où les effets GLP-1 sont les plus propres. Je le dis dans la section limites du README plutôt que de prétendre que le chiffre macro est précis.
Ce que ça veut dire, et ce qui changerait la réponse
Le résultat n'est pas « les GLP-1 n'ont aucun effet ». C'est que la façon évidente de le mesurer donne une réponse significative à l'allure trompeuse, dans la mauvaise direction, et qu'une fois l'inférence et la tendance corrigées, l'effet réel est pour l'instant trop petit pour se voir dans l'agrégat macro. La baisse par utilisateur est réelle. Celle de l'économie entière est sous le seuil de détection.
Trois choses changeraient ça. Une adoption plus élevée (les pilules GLP-1 lancées fin 2025, l'orforglipron de Lilly en avril 2026, Novo a coupé les prix US jusqu'à 70 %, un programme Medicare à 50 $/mois commence en juillet 2026). Une période post plus longue, une fois la reprise des services post-COVID dissipée. Des données carte de crédit panel au niveau catégorie qui séparent les utilisateurs des non-utilisateurs plutôt que de s'appuyer sur l'agrégat de population. La méthode est prête, le ratio signal/bruit n'y est juste pas encore au niveau macro.
Si ce projet vous a plu, le précédent de la série a appliqué le même type de test aux prix de règlement des marchés de prédiction et a trouvé un biais structurel de formulation de 32 points.
Warden : j'ai construit un agent qui gouverne vos autres agents
Une fois qu'on a une flotte d'agents IA qui agissent sur de vrais systèmes (approbation de remboursements, changement de prix, déplacement d'inventaire), qui les surveille quand l'un d'eux dérape ? Warden est le superviseur que j'ai construit pour le Google Cloud Rapid Agent Hackathon : MCP Dynatrace pour les sens, Gemini 3 pour le jugement, une vraie porte d'approbation humaine et une comptabilité en dollars honnête pour chaque incident.

Donner une mémoire à une équipe de modération
La modqueue de Reddit traite chaque modérateur comme un agent isolé qui vide une boîte de réception. Le plus dur dans la modération, ce n'est pas le volume : c'est l'isolement du cas limite, l'incohérence qui s'installe dans une équipe, et le jugement qui s'en va quand un vétéran part. Memex est la mémoire qui manquait.