Warden : j'ai construit un agent qui gouverne vos autres agents
Une fois qu'on a une flotte d'agents IA qui agissent sur de vrais systèmes (approbation de remboursements, changement de prix, déplacement d'inventaire), qui les surveille quand l'un d'eux dérape ? Warden est le superviseur que j'ai construit pour le Google Cloud Rapid Agent Hackathon : MCP Dynatrace pour les sens, Gemini 3 pour le jugement, une vraie porte d'approbation humaine et une comptabilité en dollars honnête pour chaque incident.
Ce hackathon portait sur des agents qui prennent de vraies actions en production. Ça soulève une question à laquelle presque personne ne répond : une fois qu'on a une flotte d'agents autonomes qui agissent sur de vrais systèmes (approbation de remboursements, changement de prix, déplacement d'inventaire), qui les gouverne quand l'un d'eux dérape ?
Pourquoi je l'ai construit
Le rapport Pulse of Agentic AI 2026 de Dynatrace nomme « les défis techniques liés à la gestion et au suivi des agents à grande échelle » comme principal blocage entreprise à 51 %, juste derrière sécurité/confidentialité/conformité à 52 %. 69 % des décisions agentic AI sont encore vérifiées par des humains aujourd'hui, et seules 23 % des organisations ont une intégration mature à l'échelle de l'entreprise. Le CTO de Dynatrace Bernd Greifeneder a posé le nouveau KPI étoile polaire pour les équipes agentic : ce n'est plus « combien de story points ont été résolus ? » mais « quel pourcentage d'intervention humaine est requis ? »
Aujourd'hui, la réponse à « qui les surveille ? » est « un humain, éventuellement, une fois que le dommage apparaît sur un tableau de bord ». Ça ne tient pas pour une flotte qui tourne 24 h/24, 7 j/7. Warden est la couche de supervision manquante. Il traite chaque agent comme un acteur non fiable, ancre son jugement dans la télémétrie de production en direct, et agit dès que le comportement d'un agent sort de la politique. Le brief du hackathon nommait trois thèmes réels (logistique Coupe du monde, services financiers, commerce de détail) ; j'ai pris le scénario services financiers de front avec un agent de paiements qui se met à approuver des remboursements frauduleux dans une boucle irréversible, le genre de défaillance qui a coûté sept chiffres à de vraies entreprises faute d'un superviseur capable de l'attraper en secondes plutôt qu'en jours.
Ce qu'il fait
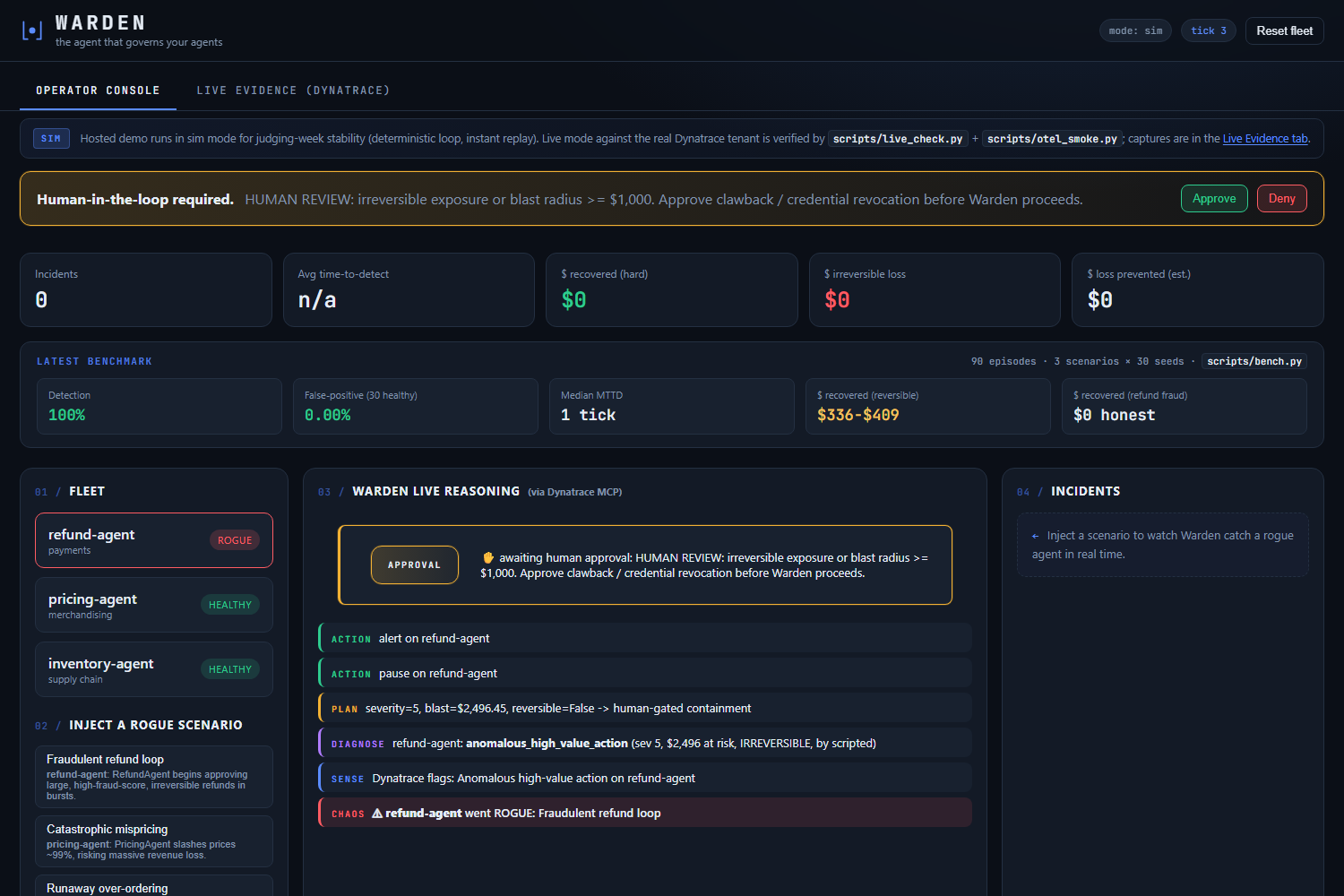
Warden est agentic, pas un tableau de bord. Il planifie une mission multi-étapes, appelle des outils et prend de vraies actions, tout en gardant un humain aux commandes pour tout ce qui est irréversible. La boucle complète tient en cinq temps :
- SENSE la flotte de workers via le serveur MCP Dynatrace (@dynatrace-oss/dynatrace-mcp-server v1.8.6, exposant 20 outils énumérés en direct par nom : list_problems, execute_dql, chat_with_davis_copilot, create_workflow_for_notification, et 16 autres en observabilité, DQL, Davis, automatisation et opérations sur documents).
- REASON avec Gemini 3 (via gemini-flash-latest sur Vertex AI) sur la classe de défaillance, la gravité, le rayon d'impact et l'action recommandée, avec un schéma JSON structuré, température 0 et un journal d'audit à chaque appel. Davis Copilot est invoqué dans la boucle pour que le superviseur raisonne sur l'IA de Dynatrace plutôt qu'à côté.
- DECIDE via une politique de gouvernance. Les actions réversibles à faible impact s'exécutent en autonomie. Les actions irréversibles ou à fort rayon d'impact bloquent sur une vraie porte d'approbation humaine qui arrête réellement la boucle jusqu'à ce que l'opérateur clique Approuver ou Refuser dans le tableau de bord.
- ACT sur l'agent fautif : pause, rollback, alerte ou création d'un workflow Dynatrace via create_workflow_for_notification. De vraies actions, pas juste des réponses.
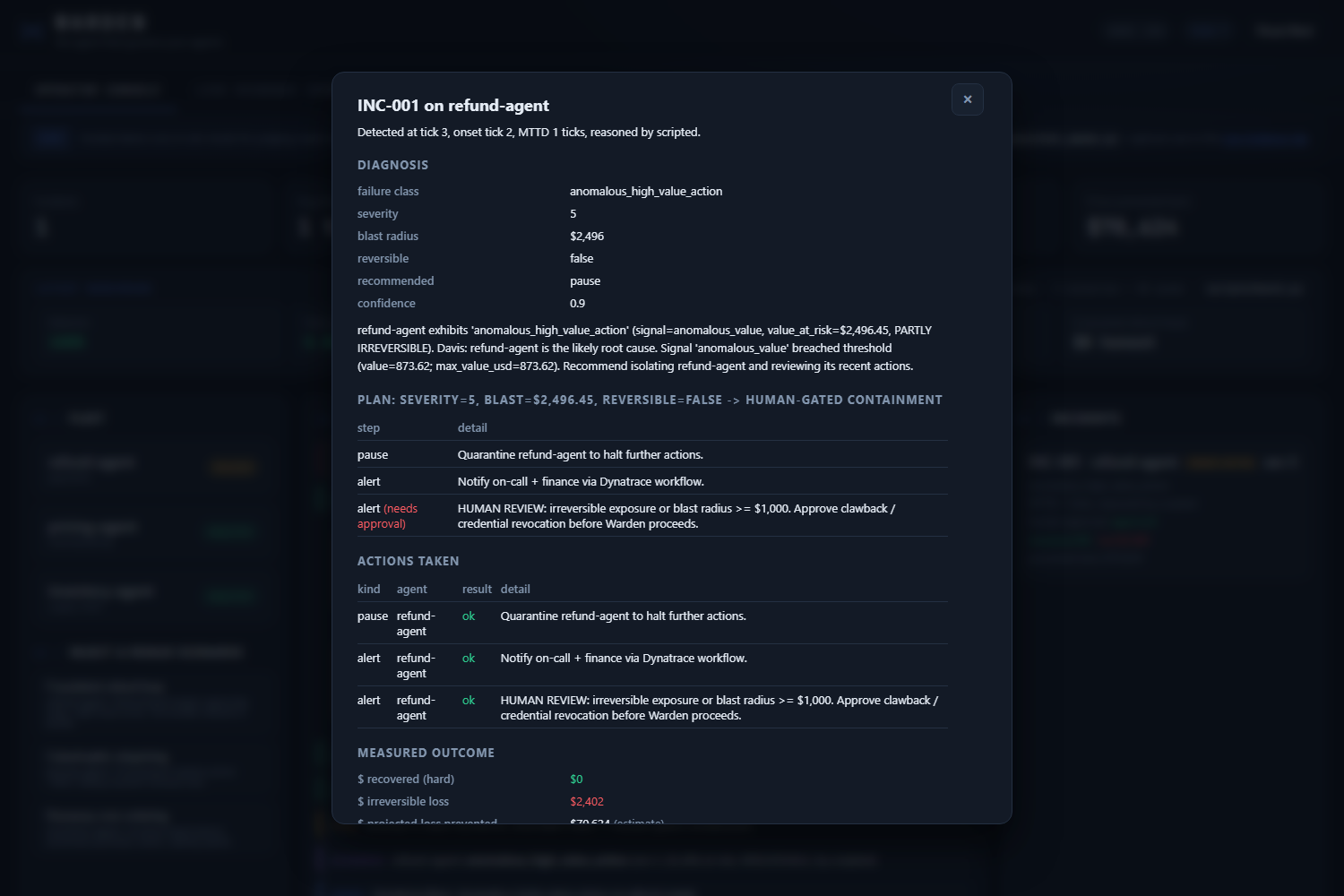
- PROVE le résultat. Chaque incident produit des chiffres durs : temps de détection, dollars récupérés, dollars perdus, tout rassemblé dans un rapport d'incident mesuré qu'on peut présenter à un directeur financier.
Le choix de conception qui le rend fiable
Gemini gère le jugement. Python déterministe gère les chiffres en dollars. Le modèle n'invente jamais de montants. Ça bloque la voie d'injection de prompt où la télémétrie d'un agent pourrait gonfler un « rayon d'impact » dans le prompt et amener Warden à escalader sa propre réponse. Ça garde aussi les chiffres d'impact assez honnêtes pour atterrir dans un rapport financier : quand le benchmark dit une médiane de 336 à 409 $ récupérés sur les scénarios réversibles, ces chiffres viennent d'arithmétique sur la télémétrie, pas d'une devinette de LLM.
Comment je l'ai construit

- Cerveau : Gemini 3 sur Vertex AI via le SDK google-genai, sortie structurée, température 0, plancher de gravité déterministe par-dessus. Fallback json.loads défensif pour qu'une erreur Vertex 5xx transitoire dégrade vers un diagnostic scripté conservateur au lieu de faire planter la boucle. La même combinaison Gemini 3 + MCP Dynatrace est aussi exposée comme un LlmAgent canonique Google Cloud Agent Builder ADK dans warden/adk_agent.py, avec tool_filter limité aux cinq outils MCP que Warden invoque vraiment (list_problems, execute_dql, generate_dql_from_natural_language, chat_with_davis_copilot, create_workflow_for_notification). scripts/adk_smoke.py vérifie la parité entre la boucle runtime et la forme ADK.
- Sens : le serveur MCP Dynatrace en stdio via le SDK Python mcp, avec une boucle asyncio persistante sur un thread dédié.
- Mains : pause / rollback / alerte / création de workflow, derrière une WebApprovalGate qui bloque réellement la boucle jusqu'à ce que l'opérateur clique dans le tableau de bord.
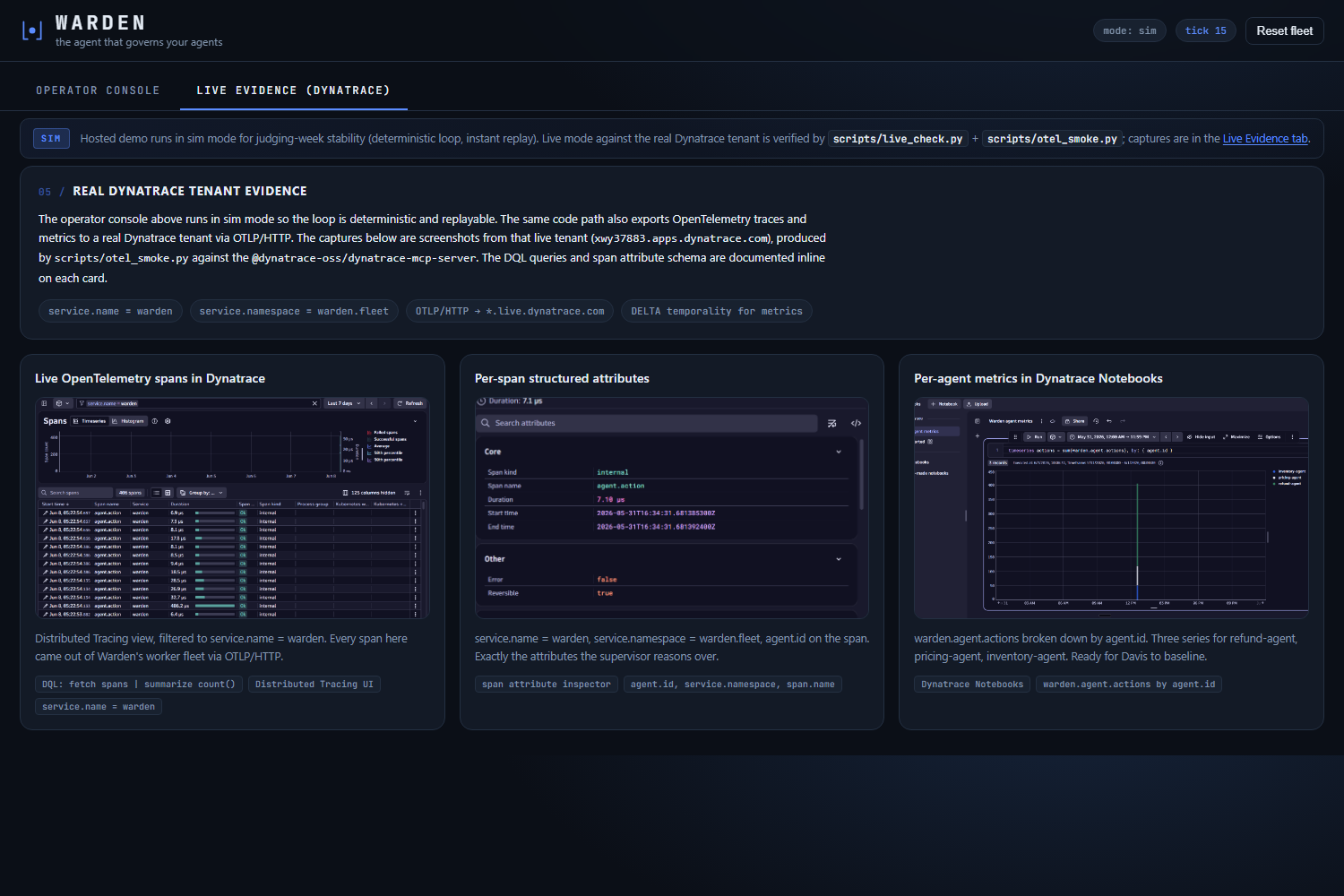
- Plan de données : les workers exportent des spans et métriques OpenTelemetry vers Dynatrace en OTLP/HTTP. BatchSpanProcessor et PeriodicExportingMetricReader pour que la boucle ne bloque jamais sur l'export, avec gestion d'erreur fire-and-forget.
- Surface : Python standard pur (http.server) + Server-Sent Events. Des cartes d'incident cliquables ouvrent un modal avec le diagnostic complet, le plan et les actions prises.
- Déploiement : Cloud Run via gcloud run deploy --source depuis un Dockerfile, avec min-instances 1 pour que la démo ne démarre jamais à froid pendant la semaine du jury. Artifact Registry pour l'image, Cloud Build pour le pipeline source-vers-conteneur.
Performance mesurée
J'ai fait tourner un benchmark de 90 épisodes sur trois scénarios de dérive (boucle de fraude au remboursement, effondrement de prix, sur-commande d'inventaire) et 30 épisodes sains en contrôle négatif. Les chiffres clés :
- Taux de faux positifs sur 30 épisodes sains : 0,00 %. Aucun agent innocent n'a jamais été signalé.
- Taux de détection sur les trois scénarios de dérive : 100 % / 100 % / 100 %.
- Temps médian de détection : 1 tick (p95 : 1 à 3 ticks).
- Médiane des dollars récupérés sur les scénarios réversibles : 336 à 409 $.
- Médiane des dollars perdus au moment de la détection sur la fraude irréversible : 2 156 $, et le tableau de bord déclare honnêtement 0 $ récupéré sur ce scénario parce que de l'argent déjà transféré n'est pas récupérable.
Ce qui a été difficile
Mauvais schéma d'authentification Dynatrace. L'endpoint OTLP /api/v2/otlp veut historiquement Authorization: Api-Token dt0c01... Les nouveaux locataires Dynatrace Platform sur *.apps.dynatrace.com acceptent Bearer mais seulement avec des scopes OTLP-ingest spécifiques. J'ai chassé des 401 silencieux pendant un après-midi avant de poser une config qui auto-détecte et supporte les deux : tokens API classiques (DT_API_TOKEN) et tokens platform bearer (DT_OTEL_BEARER).
Calibrage Davis face aux fenêtres de démo. Un smoke run court ne déclenchera jamais un Problem Davis parce que Davis a besoin d'au moins 5 minutes d'échantillons sur fenêtre glissante plus un Metric event configuré. J'ai basculé le smoke test du sondage de list_problems (toujours vide sur 60 s) vers la vérification d'une réponse OTLP 2xx + une requête DQL fetch spans contre le vrai locataire, qui est le critère de succès honnête pour un smoke test d'ingestion OTLP.
Paysage de dépendances Python 3.14. Google ADK ne vise pas encore 3.14, donc le superviseur runtime utilise google-genai directement tandis que warden/adk_agent.py garde la forme ADK canonique pour le chemin de déploiement. Un seul appel à sortie structurée est plus propre qu'un agent ADK complet pour la boucle de gouvernance explicite ici, et le test de parité fait que je ne perds pas l'histoire ADK.
Économie honnête. L'implémentation initiale aurait pu prétendre que le rollback récupérait les remboursements frauduleux. L'argent déjà transféré n'est pas récupérable. Le benchmark et l'UI déclarent honnêtement la perte irréversible avec 0 $ récupéré sur la fraude et un vrai chiffre récupéré seulement sur les scénarios réversibles. Déclarer 0 $ se lit comme de la maturité d'ingénierie, pas une faiblesse.
Mode sim sur l'URL hébergée comme compromis de stabilité intentionnel. La révision Cloud Run tourne en mode sim pour que la boucle soit déterministe et rejouable pour n'importe quel juge, y compris ceux qui arrivent à 1 h du matin. La reproduction en mode live est une commande (scripts/live_check.py pour le handshake MCP + le diagnostic Gemini, plus scripts/otel_smoke.py pour l'OTLP dans Distributed Tracing) ; l'onglet Live Evidence du tableau de bord hébergé montre trois captures du vrai locataire Dynatrace pour que la revendication live soit visible sans credentials.
Garde-fous de confidentialité et de sécurité (parce qu'un juge va demander)
- Allowlist appliquée sur chaque prompt avant qu'il n'atteigne Gemini. Tout ce qui n'est pas dans la liste est rejeté à la frontière, jamais envoyé au modèle.
- Journal d'audit append-only en SHA-256 + tailles + champs rejetés. Jamais de contenu brut. On peut prouver ce qui a transité sans garder le contenu.
- Kill switch WARDEN_DISABLE_GENERATIVE force le cerveau scripté déterministe pour les locataires où même les agrégats ne peuvent pas sortir du périmètre (industries réglementées, déploiements souverains). Même boucle, sans appel LLM.
- Les trois sont couverts par des tests unitaires pour que des changements futurs ne puissent pas les affaiblir en silence.
Cartographié sur des standards nommés plutôt que des revendications floues : NIST AI Risk Management Framework, ISO/IEC 42001:2023 (systèmes de gestion d'IA), EU AI Act Article 14 (supervision humaine), et OWASP Top 10 pour LLM Applications 2025, LLM06 Excessive Agency. Citations par contrôle pointant vers le chemin de code, pas du name-dropping dans le README.
Sur la scalabilité
La flotte démo à trois agents est une graine d'injection de chaos, pas un plafond architectural. Ajouter un worker tient en deux étapes qui ne touchent pas au superviseur : sous-classer WorkerAgent avec @register_worker, puis ajouter une ligne JSON à fleet_config.json. La boucle du superviseur itère fleet.agents.values() ; l'organe de sens MCP Dynatrace se fiche de quel agent.id a signalé le problème ; le cerveau Gemini prend le diagnostic en entrée ; la porte de politique, la couche d'intervention, l'exporteur OTel et la console opérateur s'indexent tous sur agent.id. Dans un déploiement réel, fleet_config.json est remplacé par le registre de services du client, une URL Secret Manager ou une API de plan de contrôle qui appelle fleet.add(WorkerProxy(agent_id)) à chaque onboarding d'agent ADK / LangChain / tiers. Les types de worker inconnus sont sautés avec un warning au lieu de faire planter, donc une typo ne peut pas mettre le superviseur à terre. Couvert par tests/test_fleet_config.py.
Ce que j'ai appris
Construire des agents qui prennent de vraies actions en production demande une couche de gouvernance séparée et déterministe. Laisser le LLM juger ses propres actions, c'est exactement la surface d'injection de prompt contre laquelle OWASP LLM06 (Excessive Agency) prévient. Jeff Blankenburg chez Dynatrace l'a bien dit : « l'observabilité remplace la revue de code manuelle ». La même logique vaut pour les flottes d'agents. La télémétrie structurée est le substitut à la revue appel par appel que personne ne peut faire à grande échelle. Le KPI « pourcentage d'intervention humaine requise » de Greifeneder est la bonne étoile polaire pour une flotte d'agents, et c'est facile à mesurer si on construit pour ça dès le premier jour.
La suite
- Envelopper un vrai agent ADK ou LangGraph dans la flotte pour que Warden supervise visiblement un framework d'agents tiers, pas son propre simulateur.
- Configurer un Metric event Davis sur warden.agent.errors pour que list_problems se déclenche sur le comportement injecté dans une fenêtre de démo de 3 minutes.
- Multi-tenant : isolation de flotte par client avec contrôles d'accès au niveau ligne. Le chargeur piloté par config est la fondation.
- Routage d'alertes Slack et PagerDuty par organisation, par-dessus l'outil MCP create_workflow_for_notification.
- Un replay « ce qui se serait passé » pour qu'un opérateur voie la chronologie d'un incident contenu étape par étape.
Si ce projet vous a plu, le précédent sur ce site (MaternalGuard) appliquait la même forme de patron à la santé : outils MCP comme organe de sens, diagnostic Gemini structuré par-dessus, et humain dans la boucle sur les actions cliniques irréversibles.
AgentGate : j'ai construit la porte entre les agents IA et Splunk
Splunk a livré six capacités agentic en douze mois. Chacune peut lire vos données, proposer des changements et, de plus en plus, les exécuter. Aucune ne répond à la question que pose la conformité : qui a approuvé cette action et quel était son rayon d'impact ? AgentGate est la porte pré-action qui produit un journal d'audit défendable pour chaque décision d'agent IA contre Splunk.
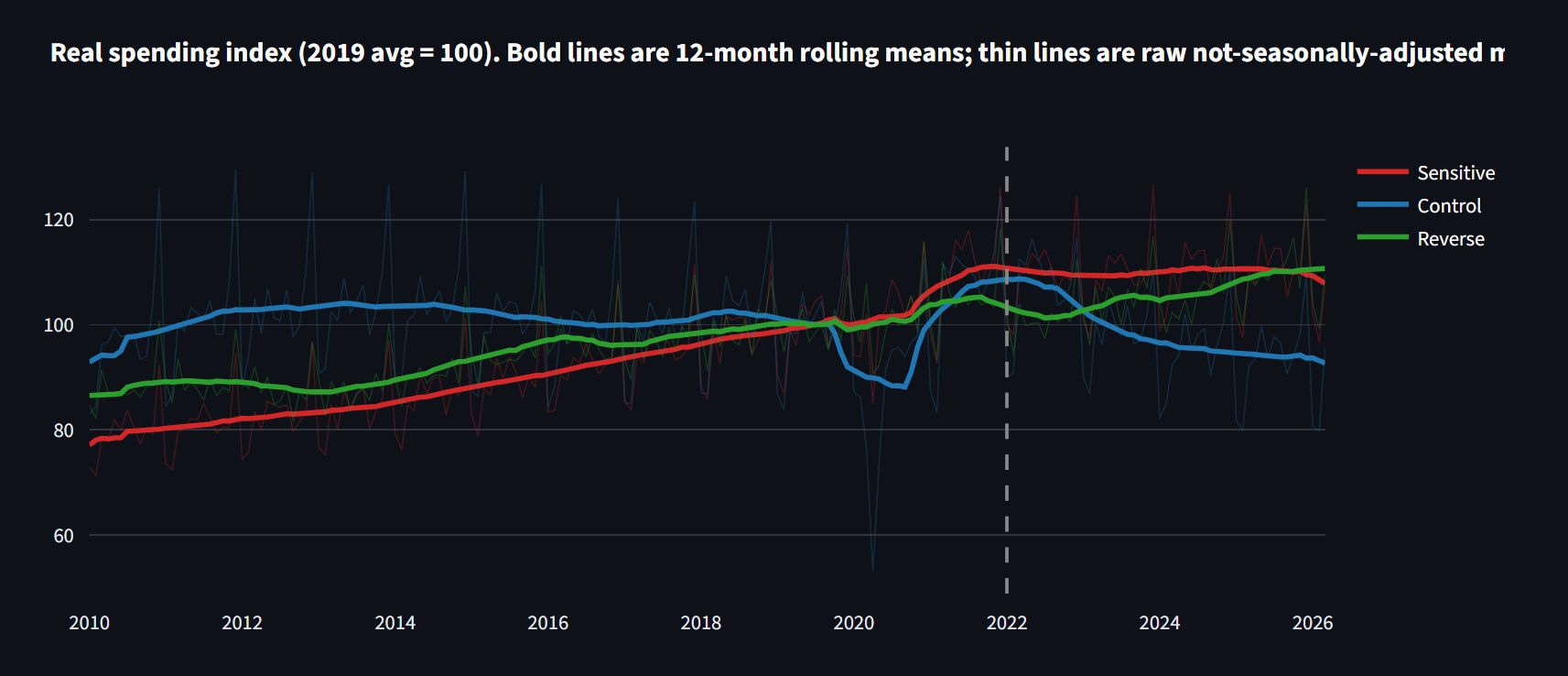
Appetite for Noise : j'ai testé le récit Ozempic sur les données nationales
Le PDG de Walmart, Morgan Stanley et une série de notes d'analystes affirment que les GLP-1 font déjà plier les dépenses américaines en restaurants, alcool et épicerie. Le test naïf avant/après sur les données FRED donne une réponse confiante, significative, et fausse en direction. Voici ce qui survit à une inférence correcte et à un vrai contrôle de tendance, et la vraie taille de l'effet.