Where Prediction Markets Systematically Fail
19,858 resolved Polymarket markets. A 32 percentage-point structural framing bias. An isotonic calibrator that beats raw market on Brier by an order of magnitude, out of sample. And a live scanner sitting on top of all of it.
The question I asked: how well-calibrated are prediction markets, where do they systematically fail, and can I use what I learn to spot mispricing on currently-open markets right now?
What I found. Three things, all from 19,858 resolved Polymarket markets analyzed end-to-end in one Zerve canvas.
Why I built it
Prediction markets keep getting cited as oracles, by journalists, by traders, by policymakers. The usual defense is that money makes them honest. I wanted to actually test that with the full resolved history, not a curated subsample, and see whether the residual error has structure I could exploit on currently-open markets.
Finding 1: A 32-point structural framing bias
Questions phrased "Will X happen?" resolve YES 29% of the time (n = 11,149). Questions phrased "Will X NOT happen?" resolve YES 61% (n = 31). t = −3.93, p = 8.4×10⁻⁵, Cohen's h = 0.66, medium effect. A five-keyword regex on the question text reveals a structural skew nobody had surfaced this clearly.
Finding 2: Settlement prices aren't predictions
So I pulled the YES-token mid price 24 hours before close from Polymarket's CLOB API and fit an isotonic regression calibrator on real pre-resolution prices. Chronologically out-of-sample: train on the older 70%, test on the newer 30% the model never saw. The calibrator achieves Brier 0.0009 versus raw market 0.0094, plus 0.0242 better ECE. It generalizes.
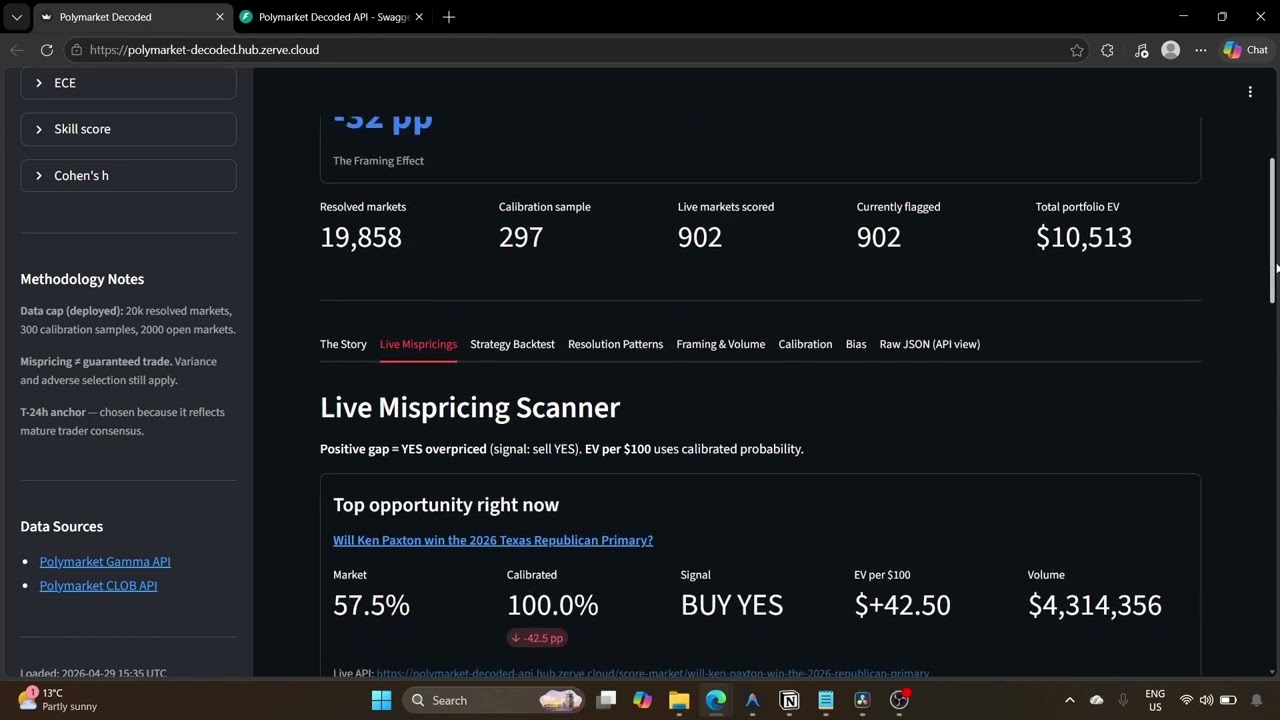
Finding 3: Applied live
The calibrator currently scores 908 open Polymarket markets, totaling $10,529 in portfolio Expected Value across all flagged signals. Backtest validation: 32 trades, 91% win rate, +27% ROI. A Bring-Your-Own-Market feature scores any Polymarket URL on demand.
How I built it
The whole pipeline lives in one Zerve canvas, from raw API pulls to the deployed Streamlit front-end. I hit the Polymarket Gamma API for the resolved-market metadata and the CLOB API for the 24-hour-pre-close YES mid prices, parked everything in DuckDB so I could run SQL over the full 19,858-row corpus without paging, and used pandas plus NumPy for the framing-bias regex and the per-bucket stats.
- Calibration: scikit-learn isotonic regression, fit on the older 70% of resolved markets, evaluated on the newer 30%.
- Stats: SciPy for the two-sample t-test and Cohen's h on the framing buckets.
- Scoring metrics: Brier score and ECE computed manually so I could log per-bucket residuals.
- Serving: FastAPI for the Bring-Your-Own-Market endpoint, Streamlit for the live scanner UI, Plotly for the calibration plots.
What was hard
Two things. First, true out-of-sample evaluation: the temptation is to k-fold split, but resolved markets are time-ordered and resolution mechanics drift, so a random split would leak. I forced a chronological 70/30 cut and only then trusted the Brier delta. Second, the Bring-Your-Own-Market endpoint had to resolve any pasted Polymarket URL to the right CLOB token mid price in under a second, which meant memoizing the Gamma slug-to-condition-id lookup and pre-warming a DuckDB view on the open universe.
Prediction markets are increasingly cited as oracles by journalists, traders, and policymakers. If they have structural biases, those biases shape decisions.
What I learned
An off-the-shelf isotonic calibrator, trained on truly out-of-sample data, beats the market by an order of magnitude on Brier. That is either real edge sitting in plain sight, or the resolution mechanism is doing something the prices do not reflect. Both are worth understanding, and neither shows up if you only look at top-line accuracy.
Why it matters
This project surfaces one bias (the framing effect), demonstrates that calibration adjustments generalize out-of-sample, and ships a live tool anyone can use today. The interesting part isn't the win rate, it's the Brier gap on data the model never saw. If oracles get cited in news cycles, the structural skew in how their questions are written deserves a name and a number.
What's next
- Add category-conditioned calibrators (politics, sports, crypto) instead of one global isotonic fit.
- Track the framing-bias effect over time to see if Polymarket's question authors correct it once it's named.
- Expose the Bring-Your-Own-Market endpoint as a public FastAPI route with a per-IP rate limit so researchers can score URLs without spinning up the Streamlit app.
- Replay the 32-trade backtest as a rolling forward-walk and report a Sharpe-style risk-adjusted edge, not just ROI.
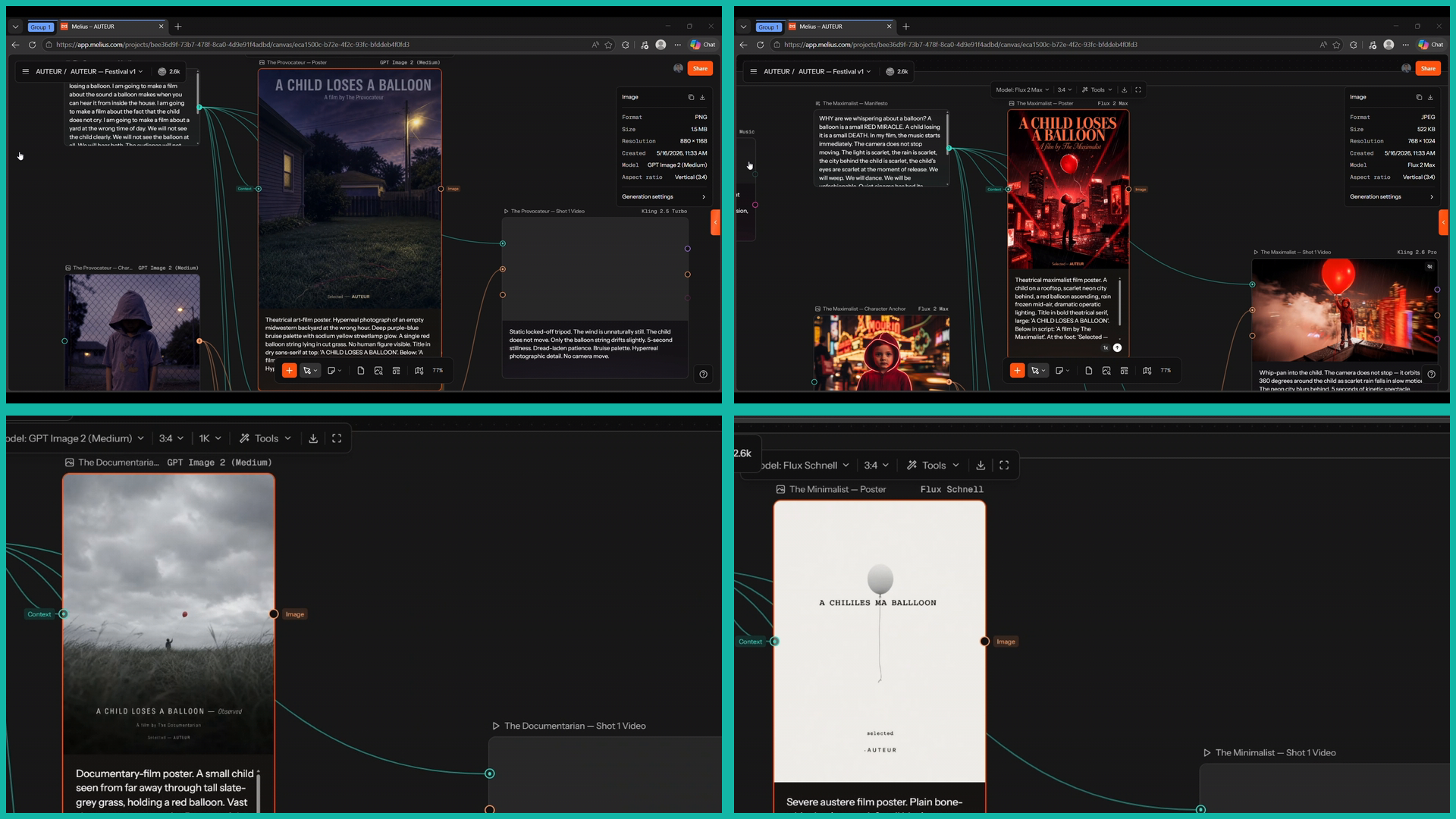
A Film Festival Where AI Models Compete as Directors
One sentence, six imaginary directors, six different model stacks. The canvas itself is the artifact, not just the final video. Built in one shot across 90 nodes and 85 edges via MCP-driven scaffolding.
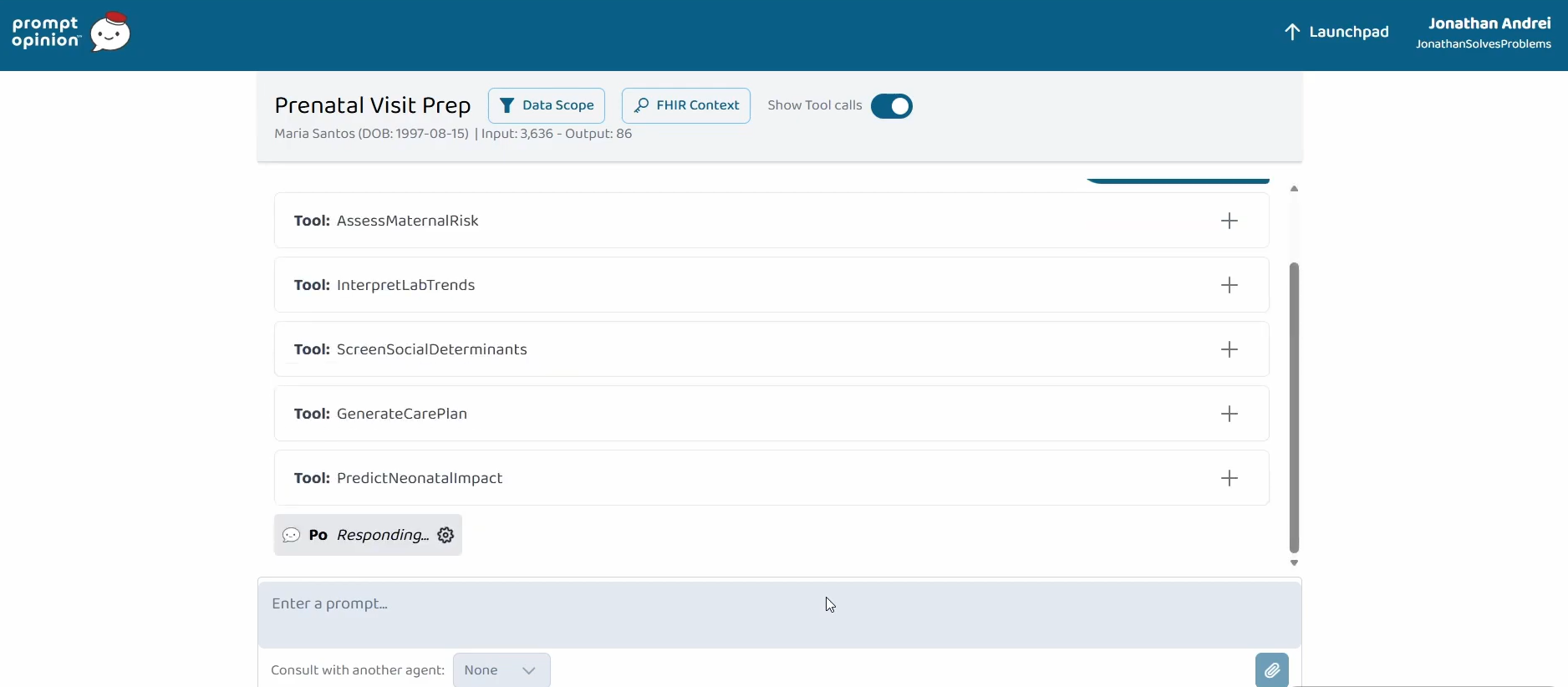
Five MCP Tools That See a Pregnancy as One Clinical Unit
Winner of Prompt Opinion's Agents Assemble: The Healthcare AI Endgame, out of 4,335 participants. US maternal mortality keeps rising and over 80% of pregnancy-related deaths are preventable, but the predictive signals live across completely different parts of the chart. I built an MCP server that aggregates them, and a Triage agent that delegates to it.