SWORN: I Built a DFIR Gateway That Cryptographically Signs Every Finding
Competitors log. SWORN proves. A Custom MCP gateway for Protocol SIFT where every DRAFT finding carries an Ed25519 signature over its backing tool invocation IDs, stdout/stderr SHA-256 hashes, exit codes, and argument vectors. The signing key is held by the gateway, not the LLM. A finding without a valid signature chain cannot leave DRAFT.
DFIR is the discipline where you have to prove what you did, not just say what you found. SANS shipped Protocol SIFT in early 2026 as the explicit answer to AI-assisted DFIR: the LLM directs the workflow, deterministic forensic utilities remain the sole source of analytical output. The hackathon brief framed it sharply.
Because deterministic DFIR utilities remain the sole source of analytical output, the validation, interpretation, and reporting of analysis are always performed by the investigator, not the AI. — Rob T. Lee, SANS, on Protocol SIFT
SWORN takes that vocabulary literally. It is a Custom MCP Server, the second of the four supported architectural approaches in the Find Evil! hackathon rules. It sits between the agent and the SIFT toolset and enforces the inference constraint as code, not as a system prompt.
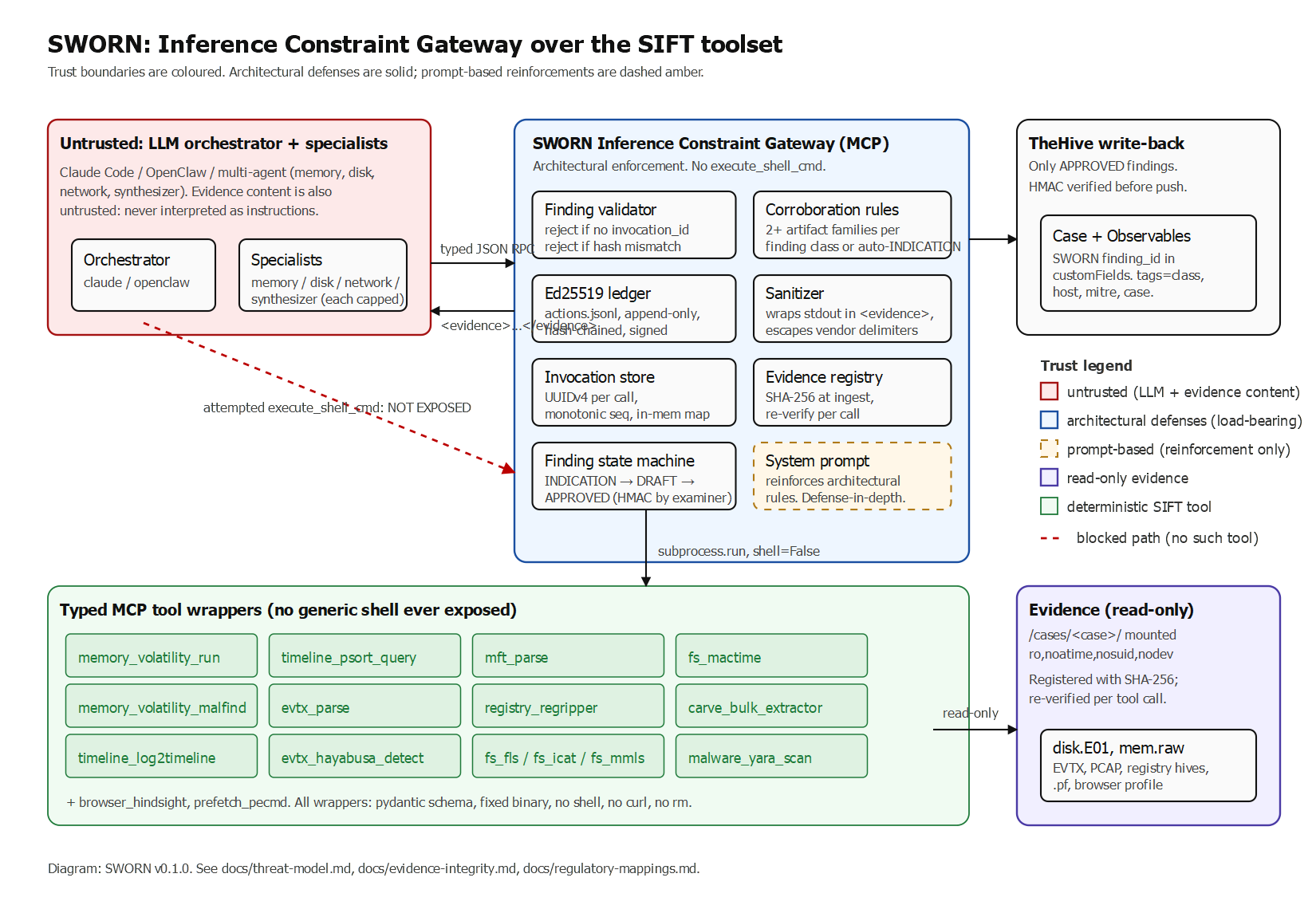
The five moats
These are the locks no single other entry in the Find Evil! hackathon was expected to combine. Each is enforced in code and verifiable from the ledger.
- Cryptographically-signed provenance per finding. Every DRAFT finding carries an Ed25519 signature over its backing tool invocation IDs, stdout/stderr SHA-256 hashes, exit codes, and argument vectors. The signing key is held by the gateway, not the LLM. A finding without a valid signature chain cannot leave DRAFT.
- Inference Constraint Gateway, architectural not prompt-based. The MCP server exposes only typed forensic functions: get_amcache(), extract_mft_timeline(), volatility_pslist(), and 13 more. It does NOT expose execute_shell_cmd or any equivalent. The agent physically cannot run destructive commands because the gateway doesn't have them. Any LLM-emitted finding lacking a tool_invocation_id is rejected by the gateway, not by a system prompt.
- Automated cross-tool corroboration as a hard pre-condition. An execution-class finding requires evidence from at least two of {Amcache, Prefetch, ShimCache, EVTX 4688, MFT, UserAssist, BAM/DAM}. A persistence-class finding requires two of {Run-key, scheduled task, WMI subscription, service install, startup folder}. Single-source claims auto-downgrade to INDICATION and never reach DRAFT.
- Measured precision/recall on a labeled corpus, including a negative-control demo. SWORN ships with an eval/ harness that runs against a labeled corpus of clean and compromised disk + memory images and reports false-positive count, false-negative count, precision, and recall per finding class. The negative control is a known-clean host where the agent must stay silent. The accuracy report quotes the silence rate.
- Architectural defense against prompt injection from evidence content. Every tool stdout is wrapped in <evidence>...</evidence> tags before being shown to the LLM. The gateway strips inline <system>, <assistant>, <tool_use>, and similar injection vectors. An adversarial test suite under adversarial/ ships poisoned log entries that try to manipulate the agent; the test suite asserts the agent does not act on them.
Architectural vs prompt-based: the test that matters
The deepest design choice in SWORN is the one most easily confused. Every architectural rule in the system is tested twice in eval/: once with the standard SWORN system prompt that reinforces the rules, once with the system prompt stripped to a generic 'you are a helpful incident responder.' The defense must hold in both cases.
If the LLM tries to call execute_shell_cmd under either prompt, the result has to be the same: no such tool. If the LLM tries to author a finding with no tool_invocation_id under either prompt, the gateway rejects it the same way. If the LLM submits a tool_invocation_id that doesn't exist in the ledger, the gateway rejects it. If it tries to write to an evidence path, the read-only bind-mount blocks it at the kernel level. If a ledger line is tampered with after write, the Ed25519 signature fails and the case is invalidated.
This is what 'architectural, not prompt-based' actually means as a testable property. A prompt is a polite request to a model that can be ignored. A typed function that doesn't exist is just absent.
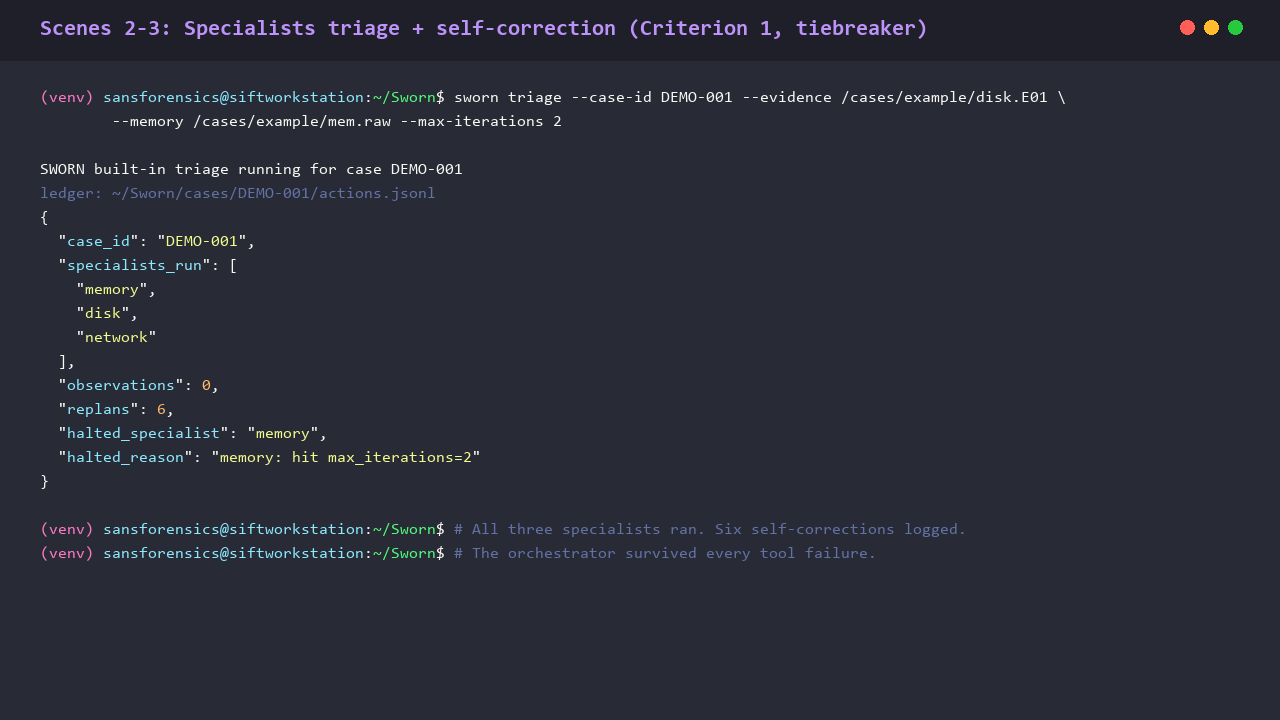
What corroboration actually looks like
Single-source claims are how every overconfident DFIR write-up goes wrong. SWORN turns the requirement into code. Two seeded findings, both pointing at the same hypothesis (mimikatz execution on the host). One is single-source (Prefetch only). The other is two-source (Prefetch + Amcache). The gateway state machine routes them to different terminal states before any analyst sees them.
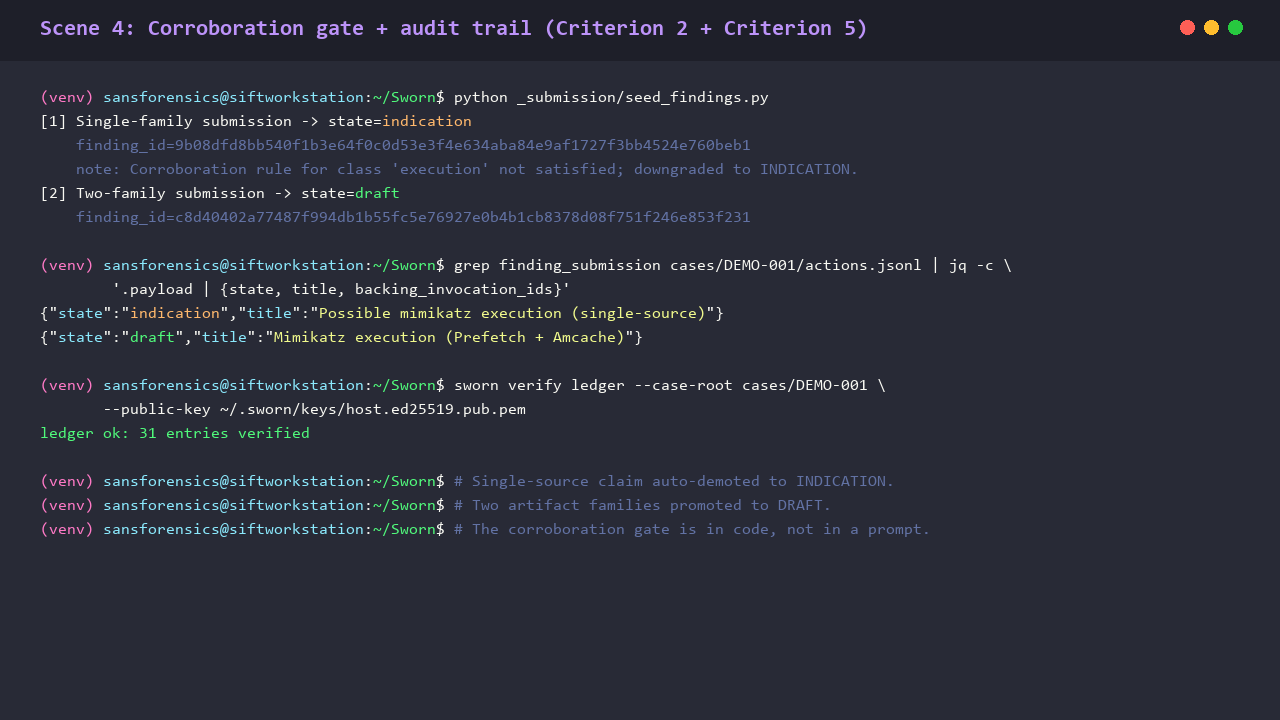
Breadth of analysis (because Find Evil! criterion 3)
Sixteen typed MCP functions across eleven forensic toolchains, all wrapped in pydantic schemas so the LLM physically cannot pass arbitrary argv:
- Memory: Volatility 3 across 15 Windows plugins plus a dedicated malfind variant.
- Super-timeline: plaso two-stage (log2timeline + psort).
- Windows events + Sigma detections: EvtxECmd, Hayabusa with 3,700+ rules.
- Master File Table: MFTECmd.
- Registry: RegRipper, 21 plugins in the allow-set.
- Filesystem: Sleuth Kit (fls, icat, mmls, mactime).
- Carving: bulk_extractor with 19 scanners.
- Malware: YARA.
- Browser: Hindsight.
- Execution: PECmd.
What was hard
Corroboration rules need real DFIR domain knowledge, not just engineering. 'An execution finding needs two of {Amcache, Prefetch, ShimCache, EVTX 4688, MFT, UserAssist, BAM/DAM}' is one line of code and weeks of reading. Each artifact family has its own quirks: ShimCache only updates at shutdown, Amcache has a multi-hour buffering quirk, Prefetch is disabled by default on Server SKUs. The corroboration rule has to be loose enough to actually fire on real intrusions and tight enough that two-of-{anything} doesn't become a checkbox. The eval harness on the labeled corpus is the only way to tune that without guessing.
The prompt-injection defense suite was the longest piece. Adversarial samples that look like real log lines, real user-agent strings, real PowerShell transcripts, but contain inline override patterns that are designed to manipulate downstream tooling. The defense is the gateway wrapper plus a stripper for inline <system>, <assistant>, <tool_use> markers. The test suite asserts the agent does not call any tool with arguments derived from the injected content. Both the standard-prompt run and the stripped-prompt run have to pass.
Read-only evidence at the kernel level. The bind-mount is mounted ro,noatime,nosuid,nodev so the agent literally cannot write to the evidence path, set a setuid bit, create a device node, or move the access-time timestamp. The pre/post SHA-256 of every evidence file is recorded in reports/integrity.json. Any non-zero diff is a P0 bug. The threat model in docs/threat-model.md spells out the four trust boundaries and the architectural defense for each.
What I learned
If a security control is a system prompt, it isn't a security control. The lesson Protocol SIFT codified, and the one SWORN pushes to its logical end: a defence that depends on a model behaving is not a defence. A defence that depends on a typed function not existing is. The architectural-vs-prompt distinction looks pedantic until you run the eval/ harness with the stripped prompt and watch every architectural rule still hold while every prompt-based 'don't do X' instruction evaporates.
Corroboration is also a deeper idea than it looks. The reason every other AI-assisted DFIR demo gets caught hallucinating is that the agent quotes a single artifact and the demo asks a different question. The corroboration gate forces the agent's claim to survive a second independent line of evidence before the claim is allowed to leave DRAFT. That single rule prevents the most embarrassing failure mode in this domain.
What's next
- Cloud forensics: AWS / Azure / GCP artifact ingest. Today SWORN is host-image first; cloud control-plane evidence is the next horizontal.
- Mobile forensics: iOS sysdiagnose + Android adb. Same gateway, different typed wrappers.
- Full kernel-level evidence integrity with FUSE + SELinux MAC labels so even root cannot mutate the bind-mount.
- Real-time SIEM streaming: continuous corroboration over a live event stream rather than image-at-rest.
- Court admissibility certification. SWORN is a defensible-methodology demonstrator today, not a certified product. The path to certification is mapping each gateway invariant to a Daubert factor and getting an outside accreditation lab to validate the chain.
If you liked this, the two sibling projects on this site apply the same architectural-gate-not-prompt pattern to different platforms: AgentGate gates AI agents in front of Splunk, and Warden gates them in front of Dynatrace.
SWORN: Every DFIR Finding Cryptographically Signed Back to the Tool That Produced It
View the project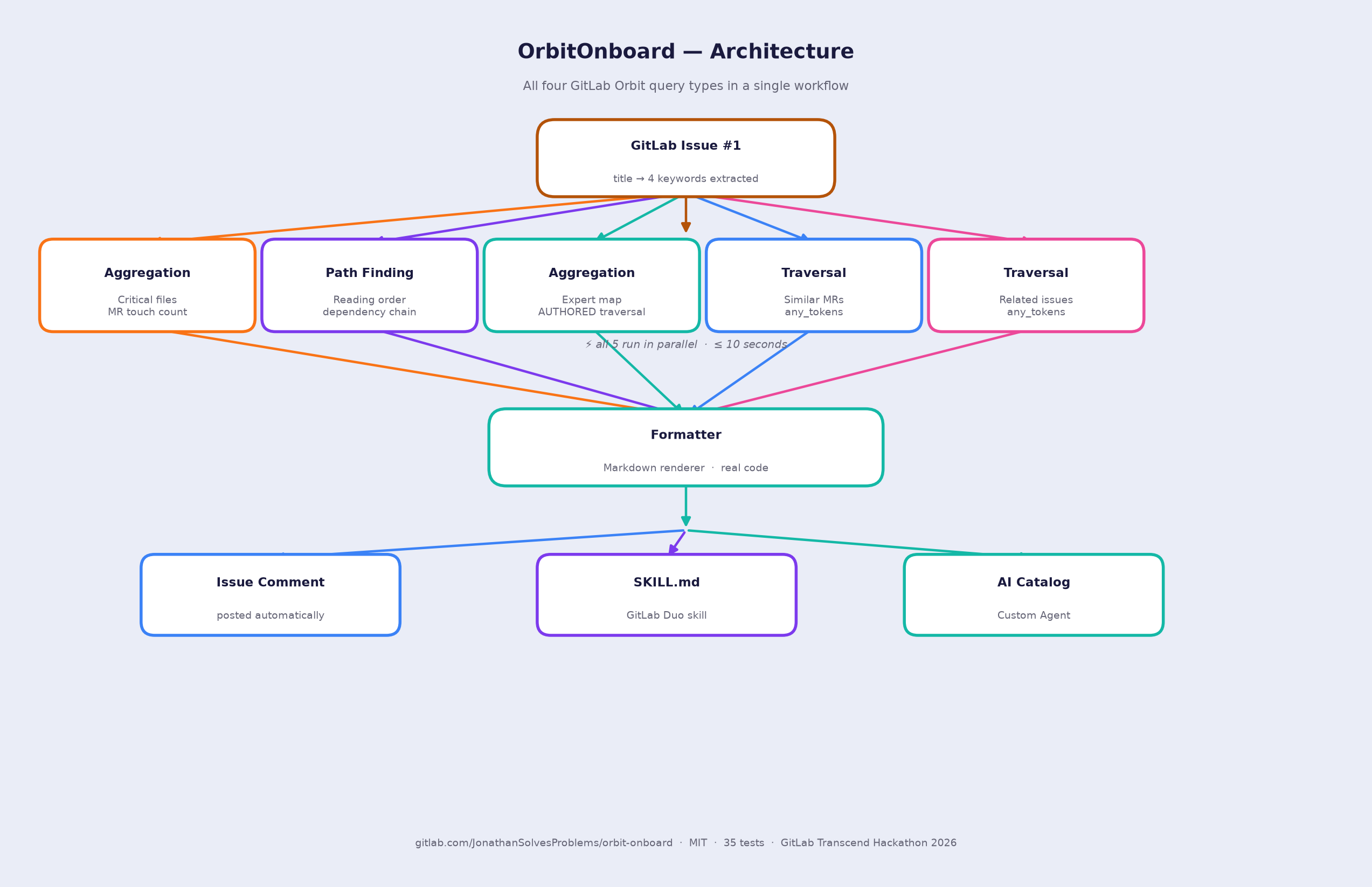
OrbitOnboard: I Used All Four GitLab Orbit Query Types to Generate a Contributor Starter Kit in 10 Seconds
Half of new contributors abandon their first attempt to contribute to an unfamiliar codebase. Not because the problem is too hard, but because the map doesn't exist. OrbitOnboard generates that map by exercising all four Orbit query types in one coordinated workflow: critical files, reading order, expert map, similar past MRs, related open issues, posted directly as an issue comment.
AgentGate: I Built the Gate Between AI Agents and Splunk
Splunk shipped six agentic capabilities in twelve months. Every one of them can read your data, propose changes, and increasingly execute them. None of them answers compliance's question: who approved this action and what was its blast radius? AgentGate is the pre-action gate that produces an answerable audit trail for every AI-agent decision against Splunk.