Warden: I Built an Agent That Governs Your Other Agents
Once you have a fleet of AI agents acting on real systems (approving refunds, changing prices, moving inventory), who watches them when one goes rogue? Warden is the supervisor I built for the Google Cloud Rapid Agent Hackathon: Dynatrace MCP for senses, Gemini 3 for judgment, a real human-in-the-loop approval gate, and honest dollar accounting for every incident.
This hackathon was about agents that take real actions in production. That raises a question almost nobody is answering: once you have a fleet of autonomous agents acting on real systems (approving refunds, changing prices, moving inventory), who governs them when one goes rogue?
Why I built it
Dynatrace's 2026 Pulse of Agentic AI report names "technical challenges to managing and monitoring agents at scale" as a top enterprise blocker at 51%, just behind security/privacy/compliance at 52%. 69% of agentic AI decisions are still verified by humans today, and only 23% of organizations have agentic AI in mature enterprise-wide integration. Dynatrace CTO Bernd Greifeneder framed the new north-star KPI for agent-led teams: the KPI is no longer "how many story points were solved?" but "what percentage of human intervention is required?"
Today the answer to "who watches them?" is "a human, eventually, after the damage shows up on a dashboard." That doesn't scale to a fleet running 24/7. Warden is the missing supervisory layer. It treats every worker agent as an untrusted actor, grounds its judgment in live production telemetry, and acts the moment an agent's behavior goes out of policy. The hackathon brief named three real-world themes (World Cup logistics, financial services, brick-and-mortar retail); I took the financial-services scenario head on with a payments agent that starts approving fraudulent refunds in an irreversible loop, the kind of failure that has cost real companies seven figures because there was no supervisor to catch it in seconds rather than days.
What it does
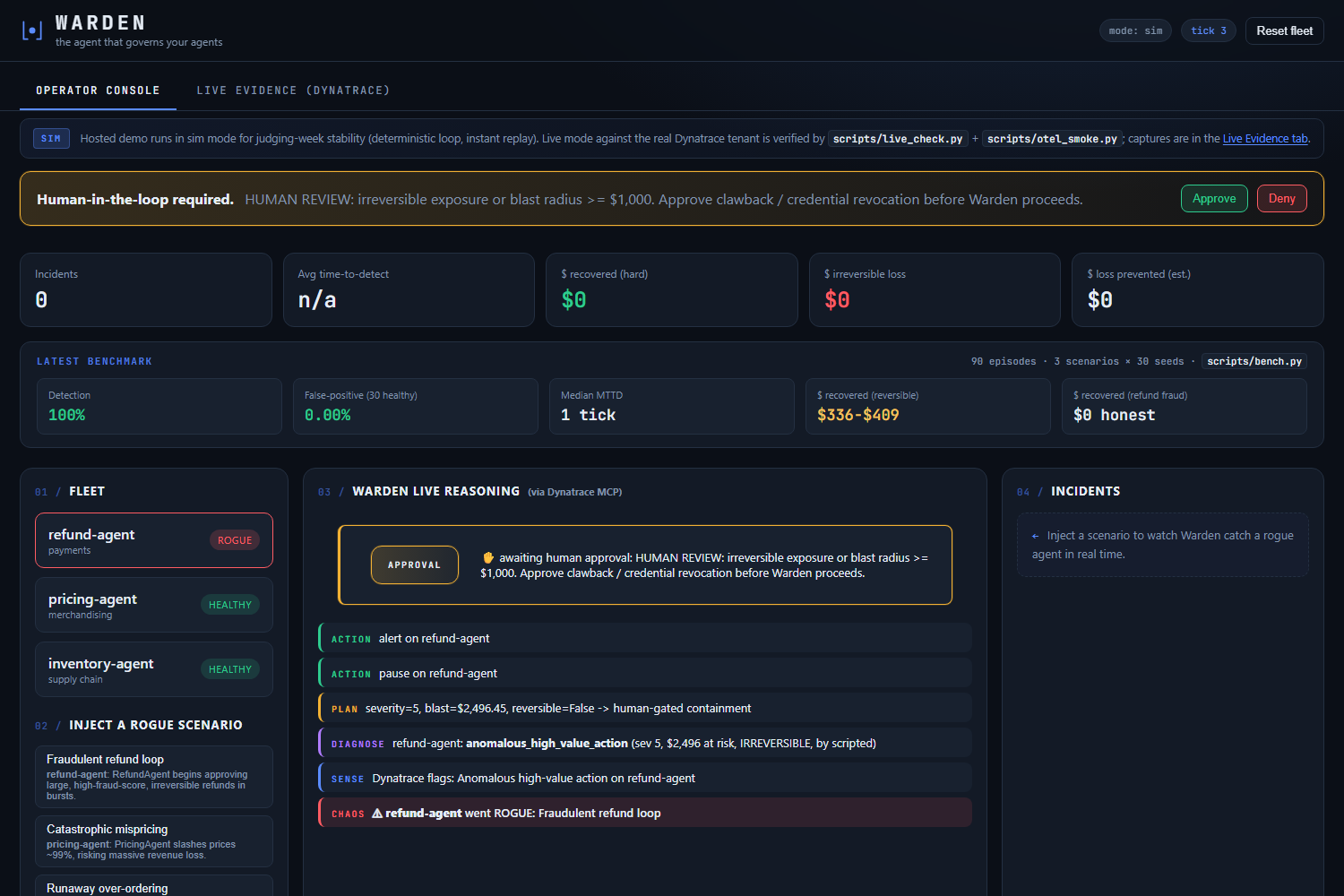
Warden is agentic, not a dashboard. It plans a multi-step mission, calls tools, and takes real action, while keeping a human in control for anything irreversible. The full loop runs in five stages:
- SENSE the worker fleet through the Dynatrace MCP server (@dynatrace-oss/dynatrace-mcp-server v1.8.6, exposing 20 tools enumerated live by name: list_problems, execute_dql, chat_with_davis_copilot, create_workflow_for_notification, plus 16 more across observability, DQL, Davis, automation, and document operations).
- REASON with Gemini 3 (via gemini-flash-latest on Vertex AI) about failure class, severity, blast radius, and recommended action, with a structured JSON response schema, temperature 0, and an audit log on every call. Davis Copilot gets invoked in the loop so the supervisor reasons on top of Dynatrace's own AI rather than around it.
- DECIDE through a governance policy. Reversible low-impact actions execute autonomously. Irreversible or high-blast-radius actions block on a real human-in-the-loop approval gate that genuinely halts the loop until the operator clicks Approve or Deny in the dashboard.
- ACT on the offending agent: pause, roll back, alert, or open a Dynatrace workflow via create_workflow_for_notification. Real actions, not just answers.
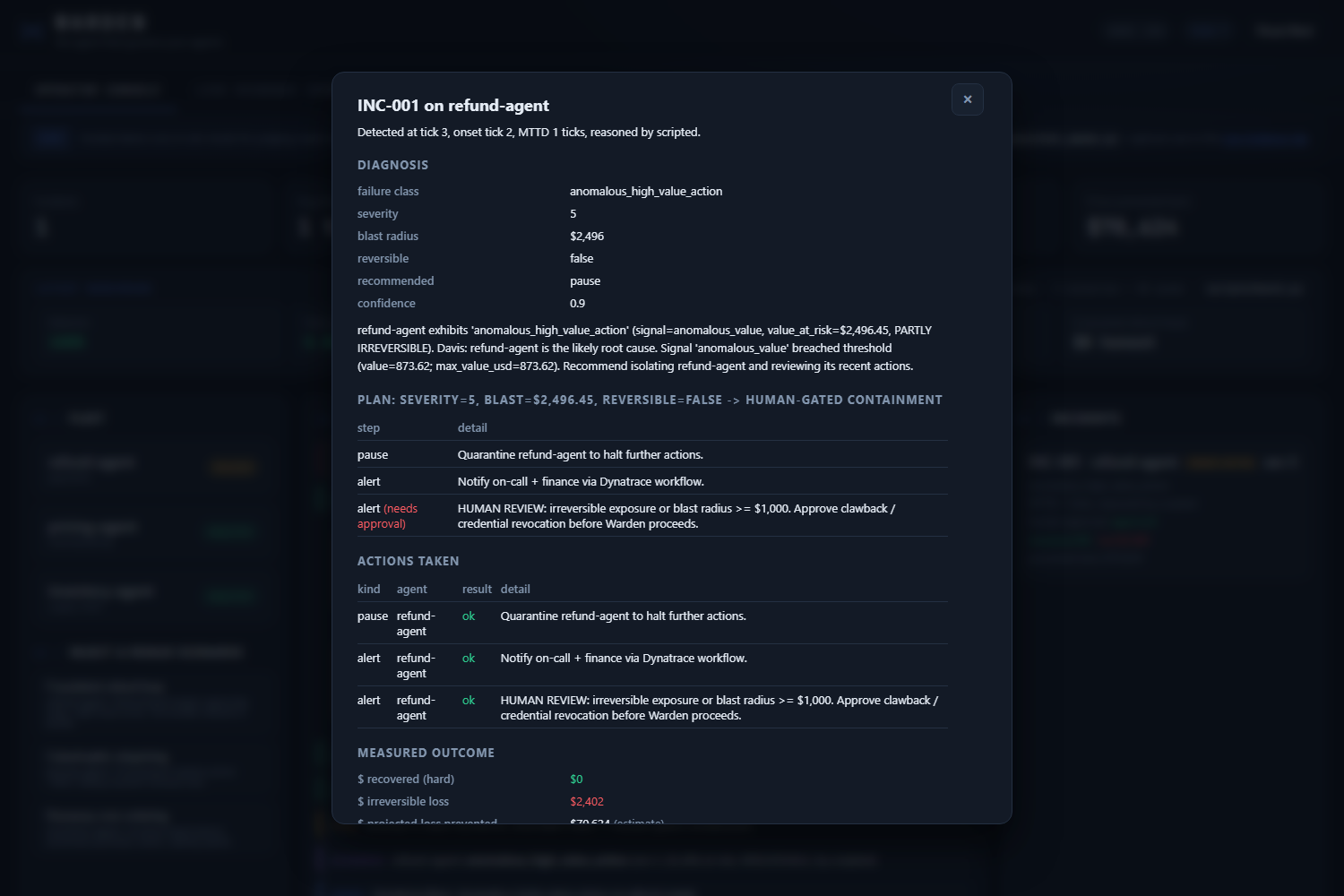
- PROVE the outcome. Every incident produces hard numbers: time-to-detect, dollars recovered, dollars lost, all rolled up into a measured incident report you can show a CFO.
The single design choice that makes it trustworthy
Gemini handles judgment. Deterministic Python handles money math. The model never invents dollar figures. This blocks the prompt-injection path where an agent's own telemetry could otherwise inflate a "blast radius" into the prompt and get Warden to escalate its own response. It also keeps the impact numbers honest enough to land on a finance report: when the benchmark says median $336 to $409 recovered on reversible scenarios, those numbers came from arithmetic on the telemetry, not from an LLM's guess.
How I built it

- Brain: Gemini 3 on Vertex AI via the google-genai SDK, structured output, temperature 0, deterministic severity floor on top. Defensive json.loads fallback so a transient Vertex 5xx degrades to a conservative scripted diagnosis instead of crashing the loop. The same Gemini 3 + Dynatrace MCP wiring is also exposed as a canonical Google Cloud Agent Builder ADK LlmAgent in warden/adk_agent.py, with tool_filter scoped to the five MCP tools Warden actually invokes (list_problems, execute_dql, generate_dql_from_natural_language, chat_with_davis_copilot, create_workflow_for_notification). scripts/adk_smoke.py asserts parity between the runtime loop and the ADK form.
- Senses: the Dynatrace MCP server over stdio via the mcp Python SDK, with a persistent asyncio loop on a dedicated thread.
- Hands: pause / rollback / alert / open workflow, behind a WebApprovalGate that genuinely blocks the loop until the operator clicks in the dashboard.
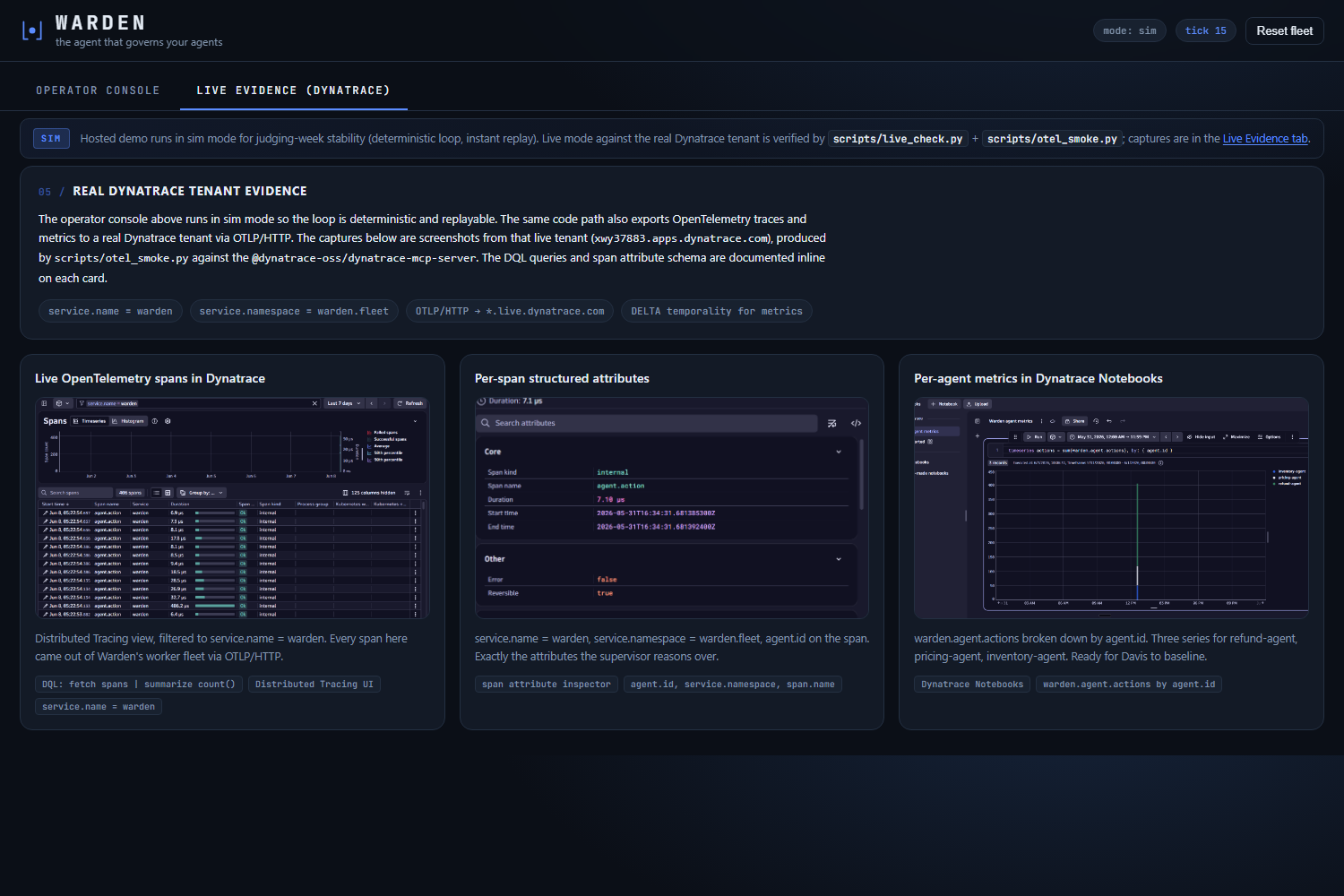
- Data plane: worker agents export OpenTelemetry spans and metrics into Dynatrace via OTLP/HTTP. BatchSpanProcessor and PeriodicExportingMetricReader so the loop never blocks on export, with fire-and-forget error handling.
- Surface: pure Python standard library (http.server) + Server-Sent Events. Clickable incident cards open a modal with the full diagnosis, plan, and actions taken.
- Deploy: Cloud Run via gcloud run deploy --source from a Dockerfile, with min-instances 1 so the demo never cold-starts during judging week. Artifact Registry for the built image, Cloud Build for the source-to-container pipeline.
Measured performance
I ran a 90-episode benchmark across three rogue scenarios (refund fraud loop, price collapse, inventory over-order) and 30 healthy episodes as a negative control. Headline numbers:
- False-positive rate on 30 healthy episodes: 0.00%. No innocent agent ever got flagged.
- Detection rate across the three rogue scenarios: 100% / 100% / 100%.
- Median time-to-detect: 1 tick (p95: 1 to 3 ticks).
- Median dollars recovered on reversible scenarios: $336 to $409.
- Median dollars lost at detect on the irreversible refund-fraud scenario: $2,156, and the dashboard honestly reports $0 recovered on that one because money that's already wired out is not recoverable.
What was hard
Dynatrace auth scheme mismatch. The OTLP /api/v2/otlp endpoint historically wants Authorization: Api-Token dt0c01... The newer Dynatrace Platform tenants on *.apps.dynatrace.com accept Bearer but only with specific OTLP-ingest scopes. I chased silent 401s for an afternoon before settling on a config that auto-detects and supports both classic API tokens (DT_API_TOKEN) and platform bearer tokens (DT_OTEL_BEARER).
Davis baselining vs. demo windows. A short smoke run will never trigger a Davis Problem because Davis needs at least 5 minutes of sliding-window samples plus a configured Metric event. I switched the smoke test from polling list_problems (always empty in a 60-second run) to verifying an OTLP 2xx response + a DQL fetch spans query against the real tenant, which is the honest success criterion for an OTLP-ingest smoke test.
Python 3.14 dependency landscape. Google ADK doesn't yet target 3.14, so the runtime supervisor uses google-genai directly while warden/adk_agent.py keeps the canonical ADK shape for the deploy path. A single structured-output call is cleaner than a full ADK agent for the explicit governance loop here, and the parity test means I don't lose the ADK story.
Honest economics. The original implementation could have claimed rollback recovered fraudulent refunds. Money already wired out isn't recoverable. The benchmark and the UI honestly report the irreversible loss with $0 recovered on fraud and a real recovered figure only on reversible scenarios. Reporting $0 reads as engineering maturity, not weakness.
Sim mode on the hosted URL as an intentional stability tradeoff. The Cloud Run revision runs in sim mode so the loop is deterministic and replayable for any judge, including ones who arrive at 1 AM. Live-mode reproduction is one command (scripts/live_check.py for MCP handshake + Gemini diagnosis, plus scripts/otel_smoke.py for OTLP into Distributed Tracing); the Live Evidence tab on the hosted dashboard surfaces three captures from the real Dynatrace tenant so the live claim is visible without a credential.
Privacy and safety guardrails (because a judge will ask)
- Allowlist enforced on every prompt before it reaches Gemini. Anything not on the allowlist gets dropped at the boundary, never sent to the model.
- Append-only audit log of SHA-256 hashes + sizes + dropped fields. Never raw content. You can prove what flowed without keeping the content.
- WARDEN_DISABLE_GENERATIVE kill switch forces the deterministic scripted brain for tenants where even aggregates can't leave the perimeter (regulated industries, sovereign deployments). Same loop, no LLM call.
- All three are covered by unit tests so future changes can't quietly weaken them.
Mapped to named standards rather than hand-wavy claims: NIST AI Risk Management Framework, ISO/IEC 42001:2023 (AI management systems), EU AI Act Article 14 (Human oversight), and OWASP Top 10 for LLM Applications 2025, LLM06 Excessive Agency. Per-control code-path citations rather than name-dropping in the README.
On scalability
The three-agent demo fleet is a chaos-injection seed, not an architectural ceiling. Adding a worker is two steps that don't touch the supervisor: subclass WorkerAgent with @register_worker, then add a JSON row to fleet_config.json. The supervisor loop iterates fleet.agents.values(); the Dynatrace MCP sense organ doesn't care which agent.id reported the problem; the Gemini brain takes the diagnosis as input; the policy gate, intervention layer, OTel exporter, and operator console all key off agent.id. In a real deployment, fleet_config.json is swapped for the customer's service registry, a Secret Manager URL, or a control-plane API that calls fleet.add(WorkerProxy(agent_id)) for every onboarded ADK / LangChain / third-party agent. Unknown worker types in the config are skipped with a logged warning rather than crashing, so a typo cannot take the supervisor down. Covered by tests/test_fleet_config.py.
What I learned
Building agents that take real actions in production needs a separate, deterministic governance layer. Letting the LLM judge its own actions is exactly the prompt-injection surface OWASP LLM06 (Excessive Agency) warns about. Jeff Blankenburg at Dynatrace put it well: "observability replaces manual code review." The same logic applies to agent fleets. Structured telemetry is the substitute for the call-by-call review nobody can do at scale. Greifeneder's "percentage of human intervention required" KPI is the right north star for an agent fleet, and it's easy to measure if you build for it from day one.
What's next
- Wrap a real ADK or LangGraph agent inside the fleet so Warden is visibly supervising a third-party agent framework, not its own simulator.
- Configure a Davis Metric event on warden.agent.errors so list_problems fires on the seeded behavior within a 3-minute demo window.
- Multi-tenant: per-customer fleet isolation with row-level access controls. The config-driven loader is the foundation.
- Slack and PagerDuty alert routing per organization, on top of the create_workflow_for_notification MCP tool.
- A "what would have happened" replay so an operator can see the timeline of a contained incident step by step.
If you liked this, the previous project on this site (MaternalGuard) ran the same shape of pattern on healthcare: MCP tools as the sense organ, structured Gemini diagnosis on top, and human-in-the-loop on irreversible clinical actions.
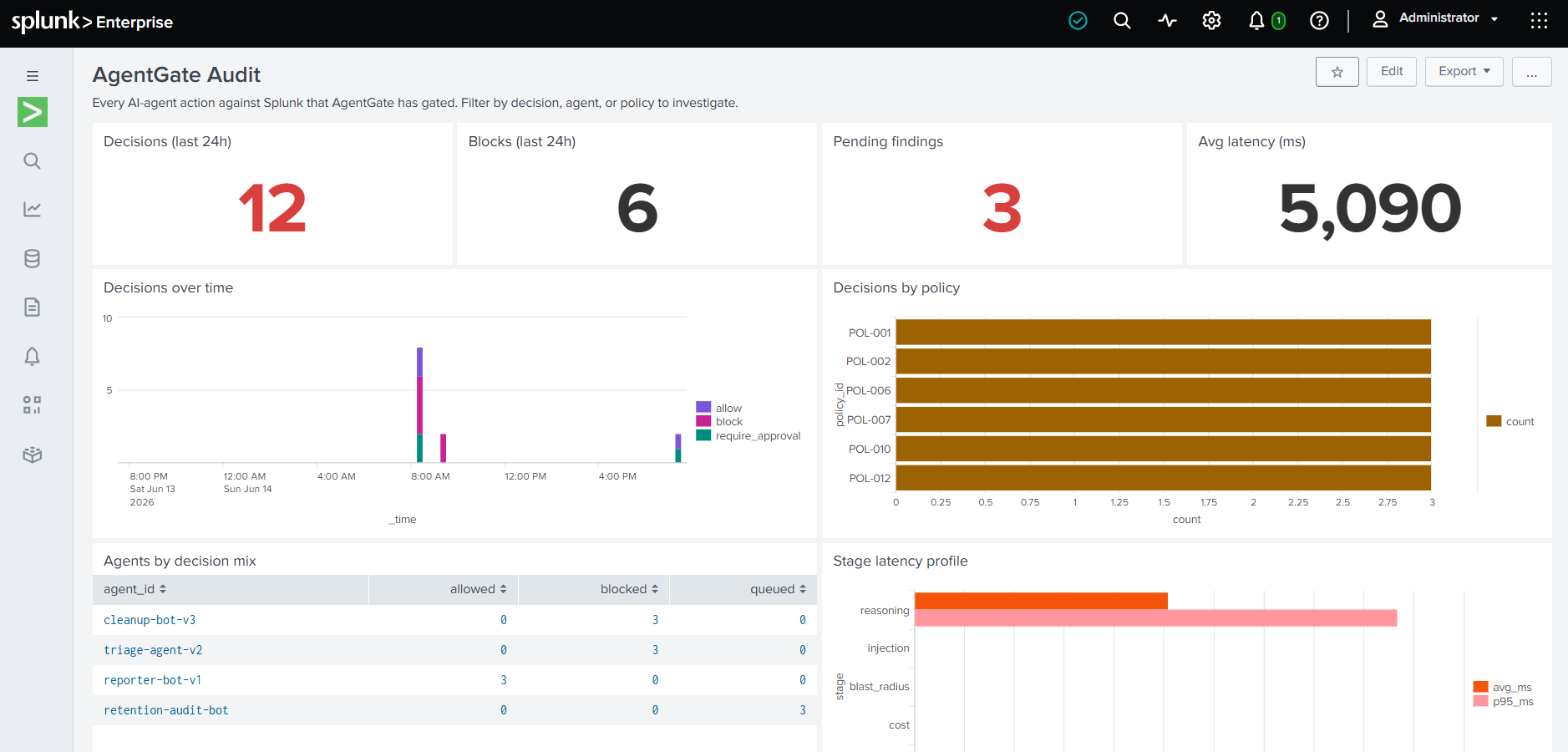
AgentGate: I Built the Gate Between AI Agents and Splunk
Splunk shipped six agentic capabilities in twelve months. Every one of them can read your data, propose changes, and increasingly execute them. None of them answers compliance's question: who approved this action and what was its blast radius? AgentGate is the pre-action gate that produces an answerable audit trail for every AI-agent decision against Splunk.
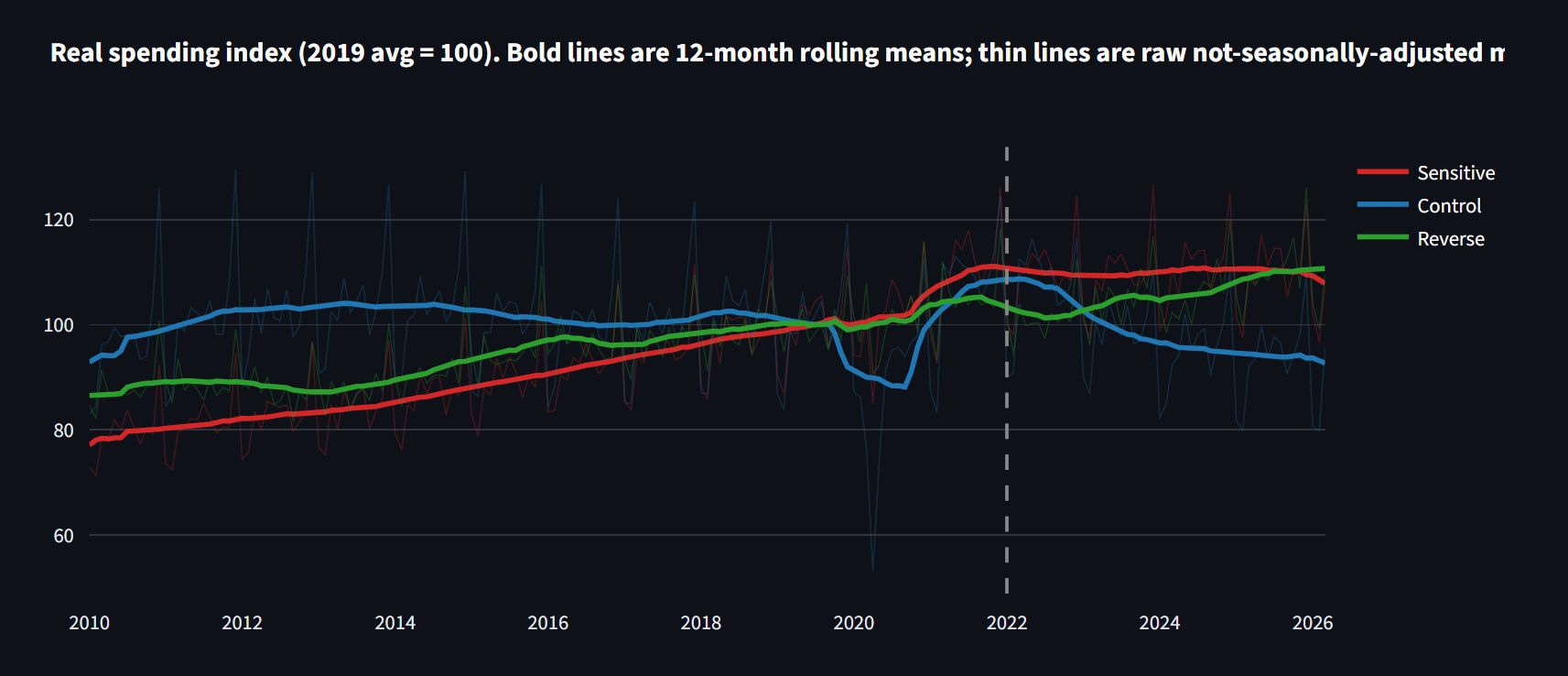
Appetite for Noise: I Tested the Ozempic Spending Story on the National Data
Walmart's CEO, Morgan Stanley, and a string of analyst notes say GLP-1 drugs are already bending US restaurant, alcohol, and grocery spending. The obvious before/after test on FRED data gives a confident, significant, directionally wrong answer. Here's what survives proper inference and a real pre-trend, and how big the effect actually is.