OrbitOnboard: I Used All Four GitLab Orbit Query Types to Generate a Contributor Starter Kit in 10 Seconds
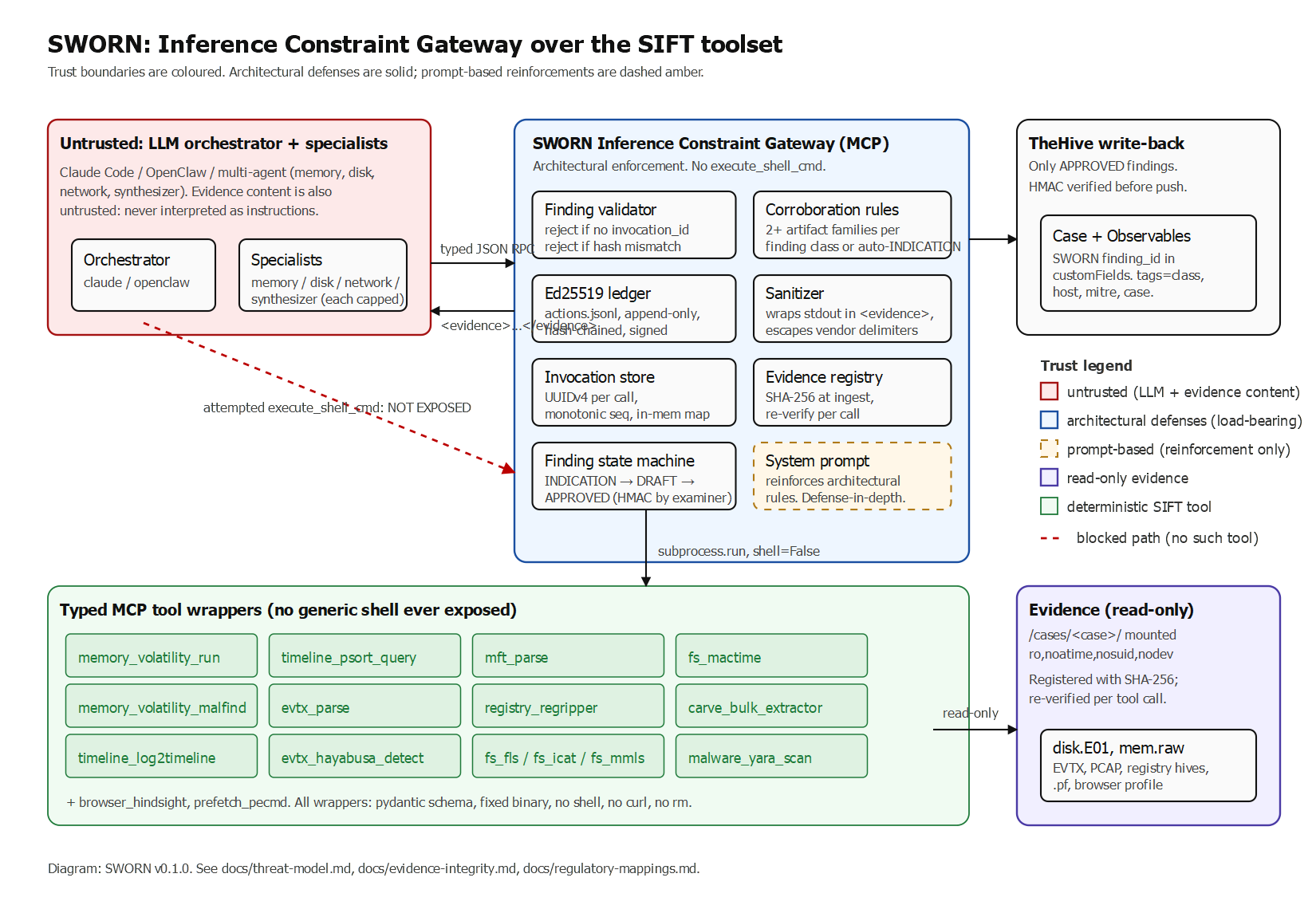
Half of new contributors abandon their first attempt to contribute to an unfamiliar codebase. Not because the problem is too hard, but because the map doesn't exist. OrbitOnboard generates that map by exercising all four Orbit query types in one coordinated workflow: critical files, reading order, expert map, similar past MRs, related open issues, posted directly as an issue comment.
Half of new contributors abandon their first attempt to contribute to an unfamiliar codebase. Not because the problem is too hard, but because the map doesn't exist. Which files matter? Who owns this area? What's the right reading order? That orientation cost is invisible, silent, and entirely avoidable.
What it produces
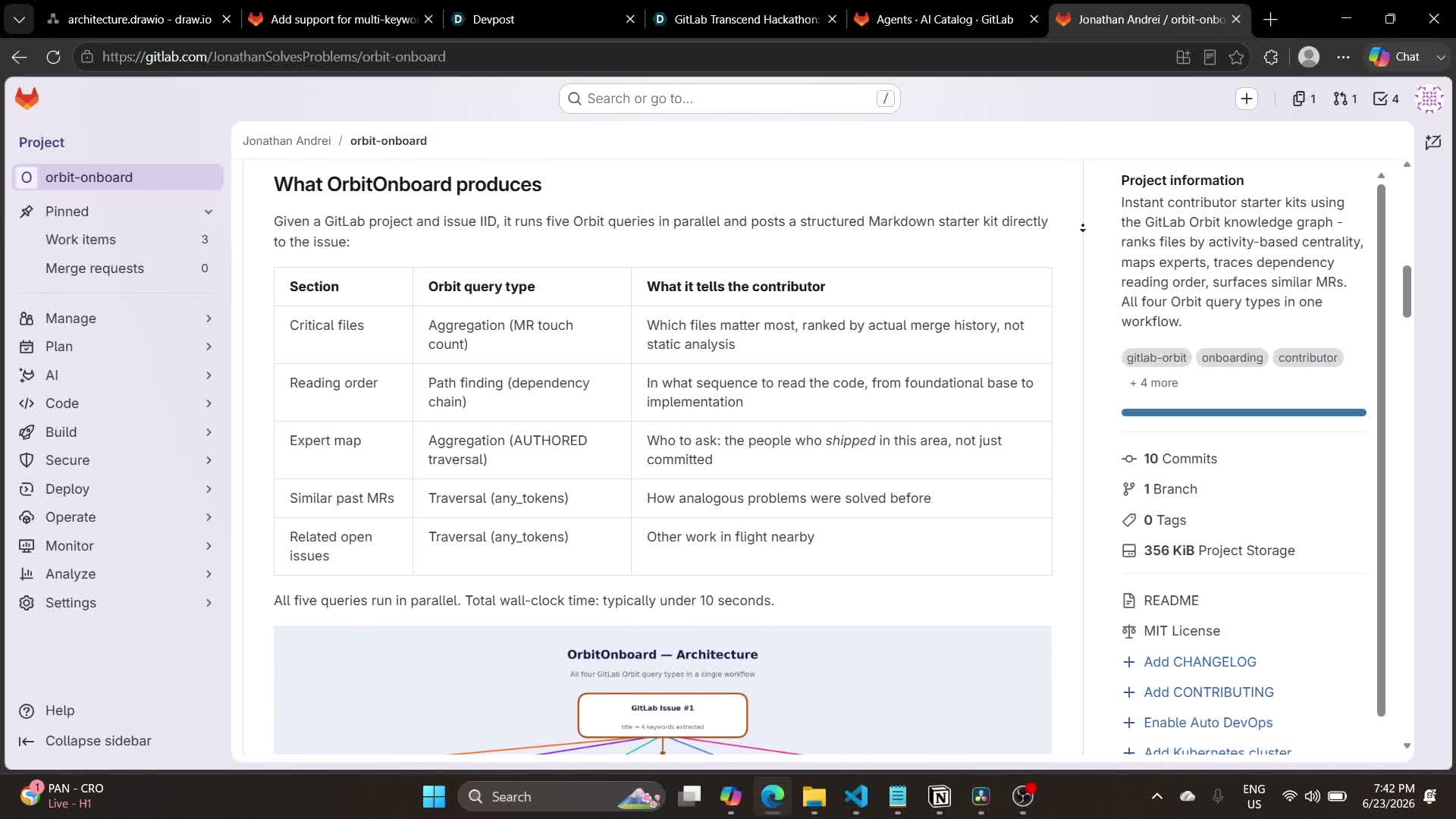
Given a GitLab project and an issue IID, OrbitOnboard runs five Orbit queries in parallel and posts a structured Markdown starter kit directly to the issue. Each section maps to an Orbit query type that's deliberately chosen for what it can tell a first-time contributor.
- Critical files (Aggregation): which files matter most, ranked by actual merge history, not static analysis.
- Reading order (Path Finding): in what sequence to read the code, from foundational base to implementation.
- Expert map (Aggregation over AUTHORED): who to ask, the people who shipped in this area, not just committed.
- Similar past MRs (Traversal with any_tokens): how analogous problems were solved before.
- Related open issues (Traversal with any_tokens): other work in flight nearby.
The differentiator: all four Orbit query types in one workflow
Most Orbit-based tools use only traversal queries. OrbitOnboard deliberately exercises all four query types because each one surfaces information no other type can.
- Aggregation: counts across the MR graph to compute activity-based centrality. Files ranked by how many merged MRs touched them. A dynamic, history-derived importance score that static analysis cannot replicate.
- Path finding: shortest-path traversal from implementation file to foundational dependencies. This is what produces the reading order, a capability unique to graph-native queries. No keyword search or file tree can generate this.
- Traversal: token-filtered node retrieval for similar past MRs and related open issues.
- Neighbors: immediate dependency inspection as a graceful fallback when path finding finds no route within the 3-hop server-enforced limit.
Using all four types in a single coordinated workflow is the core architectural decision, and what makes OrbitOnboard's output richer than any single-query approach.
Activity-based centrality, the unique insight
The file centrality module ranks files by MR touch count: how many merged MRs have modified each file in the relevant keyword area. This is activity-based centrality derived from Orbit's AUTHORED -> MergeRequest -> HAS_DIFF -> MergeRequestDiffFile edge chain.
Why this matters: static analysis tools rank files by import count or call frequency (a compile-time view). Orbit's MR touch count is a runtime view: it tells you which files the team has found important enough to change, repeatedly, over time. These are not always the same files. The most-imported utility file in a codebase isn't necessarily the one a contributor needs to read first. The file the team has reopened 47 times is.
What was hard
HAS_FILE edges between MergeRequestDiff and MergeRequestDiffFile are sparse on some GitLab instances. The first Aggregation query for critical files returned empty for the first few test projects. The fix was a fallback to a token_match traversal on File.path that approximates the same answer without depending on the rarely-populated diff-file edge. Fallbacks share the iteration-budget slot with their failed primary, so the 5-query limit is always respected.
Path finding is server-capped at 3 hops. Chains deeper than 4 levels fall back to Neighbors, which inspects immediate dependencies one level out. That's a graceful degradation rather than a hard error: the starter kit still produces a reading order, it's just shorter. The fallback ladder (Aggregation → Traversal, Path Finding → Neighbors) is documented in the SKILL.md so the Custom Agent invocation respects the same budget.
The five-query budget is hard. Every failed validation attempt counts toward it. If a query fails twice, the section is skipped with an explanatory note rather than silently omitted. That choice prevents the failure mode where a starter kit looks complete but is quietly missing a section.
Published as a Custom Agent
OrbitOnboard is also shipped to the GitLab AI Catalog as a Custom Agent. Once enabled in a project, a maintainer can invoke it directly from GitLab Duo Chat: "Use OrbitOnboard to generate a starter kit for issue #1234 in project gitlab-org/gitlab." The agent runs the same five Orbit queries, respects the 5-query iteration budget, and handles fallbacks automatically. The SKILL.md file in the repo defines its query recipes and can also be installed locally with glab skills install --global orbit-onboard.
Who this helps
- New contributors: get the map immediately instead of spending days reverse-engineering it. Reduces the abandonment rate on first contributions.
- Mentors and InnerSource hosts: send contributors a link to a generated starter kit instead of writing orientation notes by hand. The expert map names who to introduce; the reading order structures the first week.
- Maintainers: the starter kit posts automatically to the issue as a comment. No human effort required per new assignee.
- Teams scaling InnerSource: the expert map makes cross-team contribution legible. It surfaces who owns each area across organizational boundaries, so contributors know who to contact before opening an MR.
What's next
- Include reviewers, not just MR authors, in the expert map. AUTHORED is one edge type; REVIEWED is another, and reviewers often hold the deepest understanding of an area without ever authoring a top-N MR.
- Deeper path finding through a hop-budget walker that stitches together multiple 3-hop segments client-side. Server cap stays respected per query; the budget pays for stitching.
- Per-organization customization of the keyword-extraction step. Different organizations label issues differently, and the keyword set drives the entire downstream query chain.
- Pre-warmed starter kits posted as part of the issue creation lifecycle, not on demand. Same content, lower perceived latency.
If you liked this, the related project on this site (Memex) applied the same 'team knowledge made queryable' instinct to Reddit moderation: surface the team's past decisions on the borderline call you're about to make, with the consistency signal that comes from the history rather than from a guess.
OrbitOnboard: Instant Contributor Starter Kits from the GitLab Orbit Knowledge Graph
View the project