Why I Built an AI Exoplanet Classifier That Says 'I Don't Know'
An XGBoost classifier on NASA Kepler, K2, and TESS data is a Saturday afternoon. The interesting part is everything around it: three real classes (CONFIRMED, CANDIDATE, FALSE POSITIVE) plus an UNKNOWN abstention bucket, dataset upload, in-browser retraining with hyperparameter tuning, 2D exploration, and 3D system views.
Most ML demos optimize for a single number on a test set. Science doesn't work that way. A scientist would rather you flag the borderline case than confidently miscall it. So NovaTrace ships a third class (UNKNOWN) that fires when the model isn't certain enough to commit.
Why I built it
I kept seeing exoplanet classifiers framed as a binary win-rate problem: planet or not. Real Kepler, K2, and TESS catalogs are full of grazing transits, eclipsing binaries that mimic planets, and stellar variability that distorts the lightcurve. A scientist looking at one of those candidates doesn't want a forced yes-or-no. NASA itself uses three labels (CONFIRMED, CANDIDATE, FALSE POSITIVE) precisely because the middle case is real. They want the model to respect that taxonomy and say where its decision is fragile. That's the gap I wanted to close.
Confidence as a first-class citizen
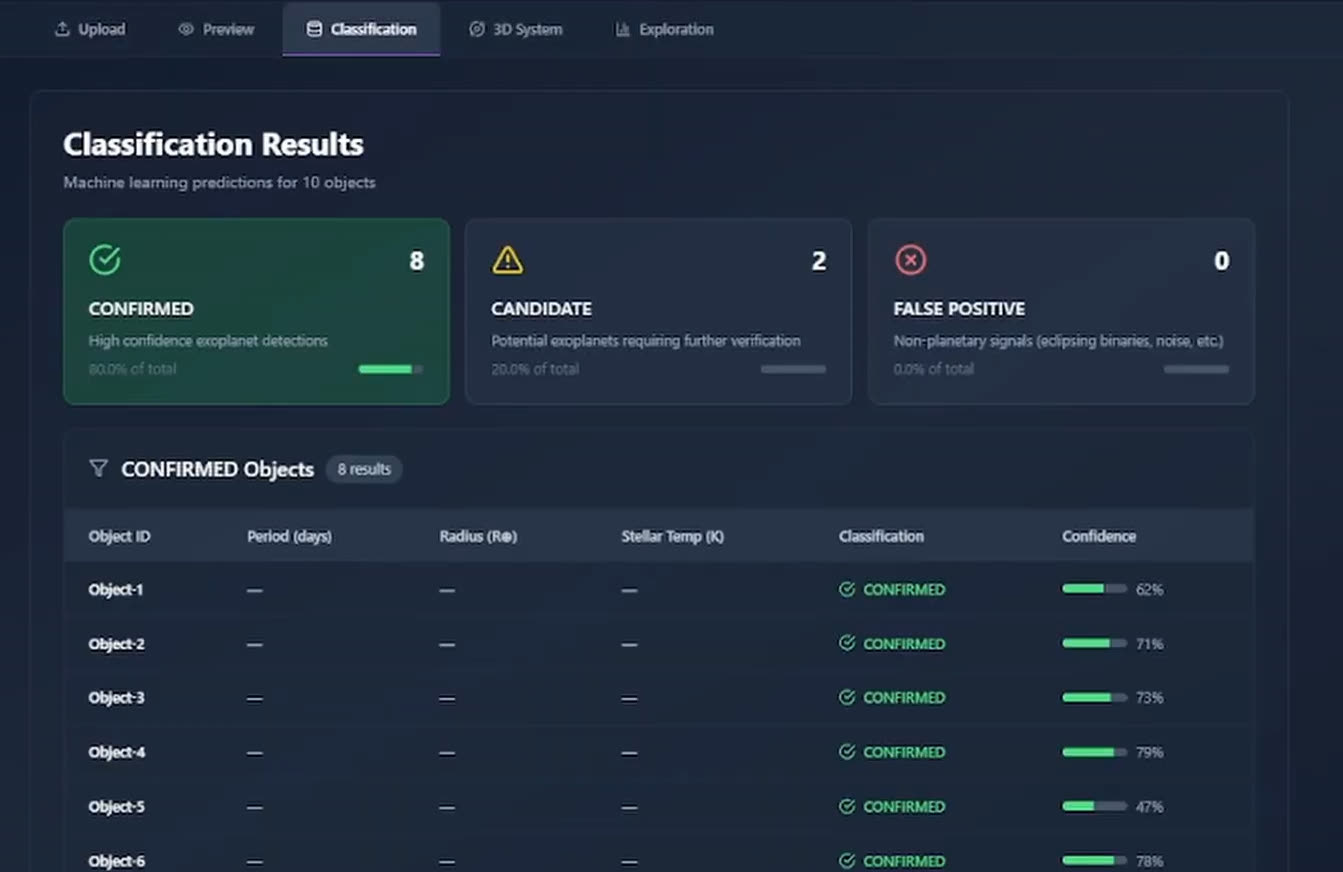
The XGBoost pipeline emits a probability across CONFIRMED, CANDIDATE, and FALSE POSITIVE. I threshold the gap between the top two: if the model is hesitating between any pair of them, I don't pretend. I push the candidate into UNKNOWN and let the user decide. That abstention bucket sits on top of NASA's three real labels, not in place of them, so the output stays compatible with how the catalogs actually talk about candidates. That's the only way an ML tool earns its way into a scientist's workflow.
What it does
- Classifies candidates from NASA's Kepler, K2, and TESS catalogs into CONFIRMED, CANDIDATE, or FALSE POSITIVE, with UNKNOWN reserved for cases the model can't separate confidently.
- Upload tab: drop in an Excel file of candidate data and run it through the trained model in the browser.
- Data Exploration tab: scatter plots and histograms over predictions and astrophysical features so a user can sanity-check what the model is reading.
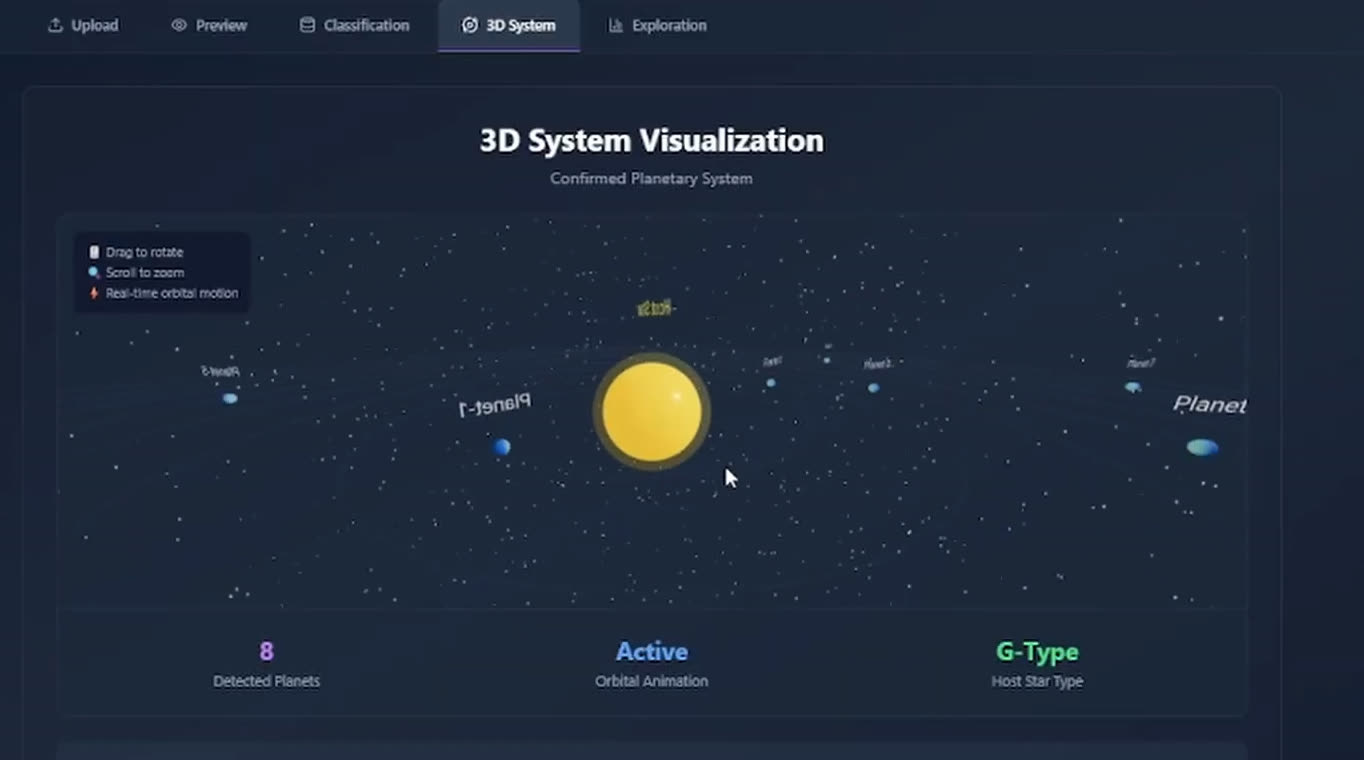
- 3D System Visualization tab: renders detected planets, host star type, system architecture, orbital dynamics, discovery method, and habitability status, with rotation, zoom, and animated orbital motion.
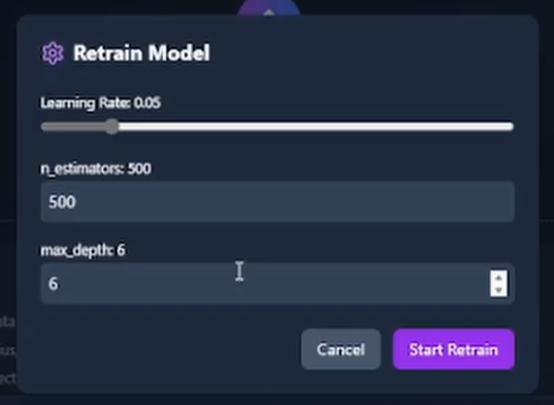
- Retrain Model tab: refit on your uploaded data and adjust hyperparameters in-browser, no Python install required.
How I built it
The classifier is an XGBoost model trained on the published Kepler, K2, and TESS object-of-interest tables, using transit-shape and stellar features (orbital period, transit depth, duration, stellar radius, effective temperature). I picked XGBoost over a deep net on purpose: tabular astrophysical features are exactly the regime where gradient-boosted trees still beat neural baselines, and the feature-importance signal falls out of the model for free, which I needed to make the visual exploration tab non-decorative.
The frontend is a React + TypeScript + Tailwind app with Three.js for the 3D system view and SVG charts for the 2D exploration tab. The backend serves predictions and handles retraining requests asynchronously so the UI never blocks while a new model fits on uploaded data.
Three.js as a credibility tool
Confirmed systems get rendered in real-time 3D: detected planets, host star type, system architecture, orbital dynamics, the discovery method that flagged the system, and habitability status. It's not eye candy, it's a way for the user to sanity-check the classifier against star-and-planet geometry they already know. If the model says CONFIRMED for a system whose 3D view looks wrong (impossible orbit, mismatched host star type), that's information.
What was hard
Picking the UNKNOWN threshold was the real engineering problem. Too tight and almost everything falls into UNKNOWN, which is useless. Too loose and the third class never fires, which is dishonest. I tuned it against a held-out slice of the catalog so the UNKNOWN bucket would catch the candidates the model genuinely couldn't separate, not just dampen overall accuracy.
Letting the user retrain from the browser, on their own uploaded data, with adjustable hyperparameters, added another constraint: the training job had to be cheap enough to run on demand. I capped the feature set and the training subset size so a retrain finishes in seconds, not minutes, and the new model swaps in atomically without dropping requests. That kept the Retrain Model tab usable as a live tool instead of a 'come back in five minutes' form.
What I learned
Calibrated abstention is a more useful feature than a higher F1. The moment I added UNKNOWN on top of NASA's three real classes and paired it with the Data Exploration scatter plots and histograms, the tool stopped feeling like a demo and started feeling like something both a researcher and an enthusiast could use to triage a candidate list.
What's next
- Ingest raw lightcurves directly instead of only the precomputed feature tables.
- Add a calibration plot so users can see how well UNKNOWN tracks actual model uncertainty.
- Compare XGBoost against a small transformer baseline on the same features as a sanity check.
Turning a Phone into a Director Workflow
Most AI generators want you to prompt one image at a time. Shot Supervisor flips it: a project breaks down into scenes, scenes into shots, and Bria FIBO's deterministic JSON-native control keeps the visual language consistent across all of them.

Why I Turned a Steam Deck into a 3D Printer Console
Winner of the OpenAI Open Model Hackathon, out of 8,652 participants: gpt-oss models running offline on a Steam Deck, voice control through Vosk, STL viewing in OpenGL, and OctoPi for the actual printing. From 'print me a hook for my desk' to a hook on the build plate.