Là où les marchés de prédiction échouent systématiquement
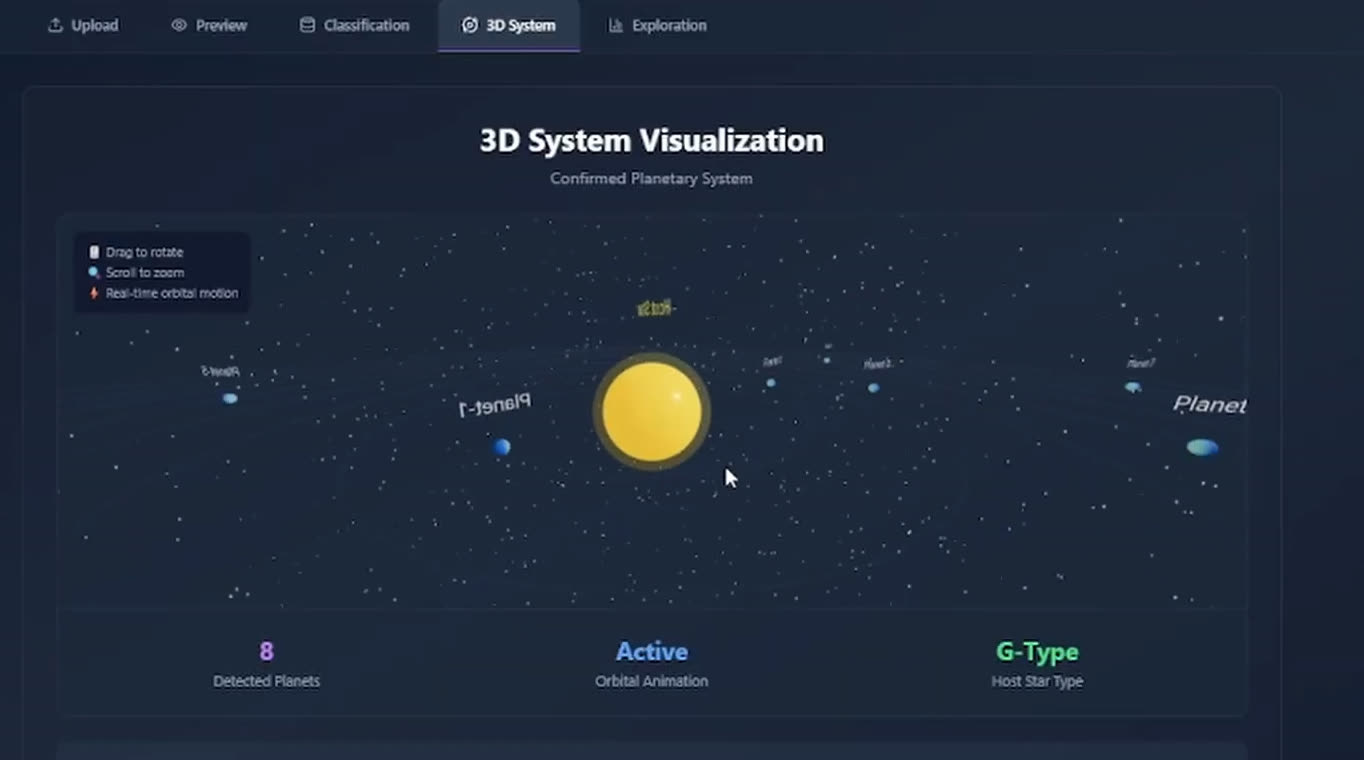
19 858 marchés Polymarket résolus. Un biais de formulation structurel de 32 points. Un calibrateur isotonique qui bat le marché brut sur le Brier d'un ordre de grandeur, en hors-échantillon. Et un scanner en direct par-dessus.
La question que je posais : à quel point les marchés de prédiction sont-ils bien calibrés, où échouent-ils systématiquement, et puis-je m'en servir pour repérer du mispricing sur des marchés actuellement ouverts ?
Ce que j'ai trouvé. Trois choses, toutes issues de 19 858 marchés Polymarket résolus, analysés de bout en bout dans un même canvas Zerve.
Pourquoi je l'ai construit
Les marchés de prédiction sont sans cesse cités comme des oracles, par les journalistes, les traders et les décideurs publics. La défense habituelle, c'est que l'argent les rend honnêtes. Je voulais vraiment tester ça sur l'historique résolu complet, pas sur un sous-échantillon trié, et voir si l'erreur résiduelle a une structure que je peux exploiter sur des marchés actuellement ouverts.
Constat 1 : Un biais de formulation structurel de 32 points
Les questions formulées « Will X happen? » résolvent OUI 29 % du temps (n = 11 149). Les questions « Will X NOT happen? » résolvent OUI 61 % (n = 31). t = −3,93, p = 8,4×10⁻⁵, h de Cohen = 0,66, effet moyen. Une regex de cinq mots-clés sur le texte de la question révèle un biais structurel que personne n'avait mis en évidence aussi nettement.
Constat 2 : Les prix de règlement ne sont pas des prédictions
J'ai donc tiré le prix médian du jeton YES 24 heures avant la clôture depuis l'API CLOB de Polymarket et ajusté un calibrateur de régression isotonique sur de vrais prix avant résolution. En hors-échantillon chronologique : 70 % anciens à l'entraînement, 30 % récents en test, jamais vus du modèle. Le calibrateur atteint un Brier de 0,0009 contre 0,0094 pour le marché brut, et une ECE améliorée de 0,0242. Il généralise.
Constat 3 : Appliqué en direct
Le calibrateur note actuellement 908 marchés Polymarket ouverts, totalisant 10 529 $ d'Expected Value de portefeuille sur l'ensemble des signaux signalés. Validation en backtest : 32 trades, 91 % de réussite, +27 % de ROI. Une fonction Bring-Your-Own-Market évalue n'importe quelle URL Polymarket à la demande.
Comment je l'ai construit
Tout le pipeline vit dans un seul canvas Zerve, des appels d'API bruts jusqu'au front-end Streamlit déployé. J'ai frappé l'API Gamma de Polymarket pour les métadonnées de marchés résolus et l'API CLOB pour les prix médians YES 24 h avant clôture, j'ai tout déposé dans DuckDB pour pouvoir faire du SQL sur le corpus complet de 19 858 lignes sans pagination, et j'ai utilisé pandas et NumPy pour la regex du biais de formulation et les stats par bucket.
- Calibration : régression isotonique de scikit-learn, ajustée sur les 70 % de marchés résolus les plus anciens, évaluée sur les 30 % plus récents.
- Stats : SciPy pour le test t à deux échantillons et le h de Cohen sur les buckets de formulation.
- Métriques de scoring : Brier et ECE calculés à la main pour pouvoir loguer les résidus par bucket.
- Service : FastAPI pour l'endpoint Bring-Your-Own-Market, Streamlit pour l'UI du scanner en direct, Plotly pour les graphes de calibration.
Ce qui a été difficile
Deux choses. D'abord, la vraie évaluation hors-échantillon : la tentation est de faire un k-fold, mais les marchés résolus sont ordonnés dans le temps et la mécanique de résolution dérive, donc un split aléatoire fuirait. J'ai forcé une coupe chronologique 70/30 et c'est seulement là que j'ai fait confiance au delta de Brier. Ensuite, l'endpoint Bring-Your-Own-Market devait résoudre n'importe quelle URL Polymarket collée vers le bon prix médian du token CLOB en moins d'une seconde, ce qui voulait dire mémoïser le lookup slug-vers-condition-id de Gamma et préchauffer une vue DuckDB sur l'univers ouvert.
Les marchés de prédiction sont de plus en plus cités comme des oracles par les journalistes, les traders et les décideurs publics. S'ils ont des biais structurels, ces biais façonnent les décisions.
Ce que j'ai appris
Un calibrateur isotonique sur étagère, entraîné sur des données réellement hors-échantillon, bat le marché d'un ordre de grandeur sur le Brier. C'est soit un vrai edge qui traîne au grand jour, soit le mécanisme de résolution fait quelque chose que les prix ne reflètent pas. Les deux méritent d'être compris, et ni l'un ni l'autre n'apparaît si on ne regarde que la précision globale.
Pourquoi c'est important
Ce projet met en évidence un biais (l'effet de formulation), démontre que les ajustements de calibration généralisent en hors-échantillon, et livre un outil en direct utilisable dès aujourd'hui. La partie intéressante n'est pas le taux de réussite, c'est l'écart de Brier sur des données que le modèle n'a jamais vues. Si les oracles sont cités dans les cycles d'actualité, le biais structurel dans la façon dont leurs questions sont rédigées mérite un nom et un chiffre.
La suite
- Ajouter des calibrateurs conditionnés par catégorie (politique, sport, crypto) au lieu d'un seul ajustement isotonique global.
- Suivre l'effet du biais de formulation dans le temps pour voir si les auteurs de questions de Polymarket le corrigent une fois nommé.
- Exposer l'endpoint Bring-Your-Own-Market comme route FastAPI publique avec une limite de débit par IP pour que les chercheurs puissent évaluer des URL sans lancer l'app Streamlit.
- Rejouer le backtest de 32 trades en forward-walk glissant et rapporter un edge ajusté au risque de type Sharpe, pas juste le ROI.
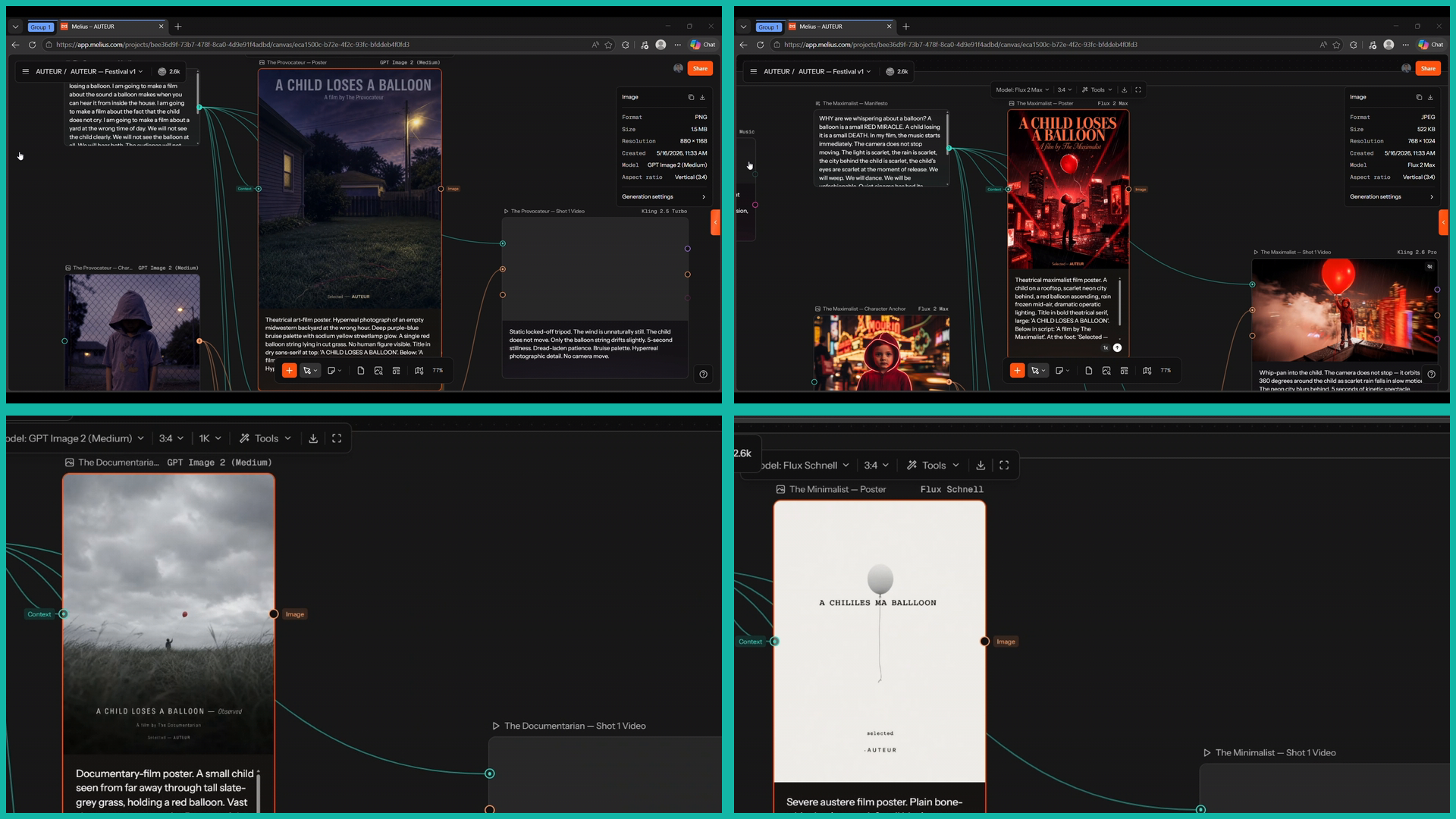
Un festival où les modèles d'IA s'affrontent comme réalisateurs
Une phrase, six réalisateurs imaginaires, six piles de modèles différentes. Le canvas lui-même est l'œuvre, pas seulement la vidéo finale. Échafaudé en un seul coup sur 90 nœuds et 85 arêtes via un script piloté par MCP.
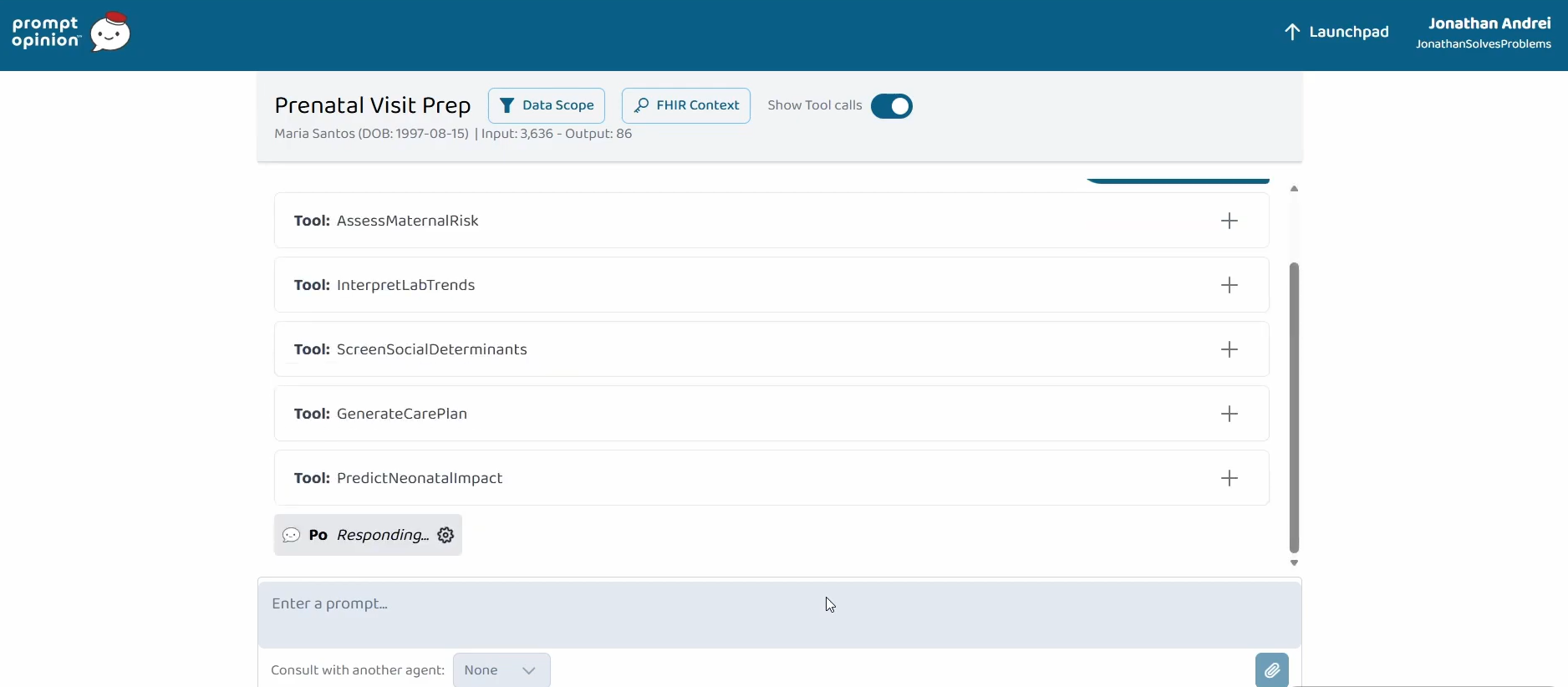
Cinq outils MCP qui voient une grossesse comme une seule unité clinique
Lauréat d'Agents Assemble : The Healthcare AI Endgame de Prompt Opinion, parmi 4 335 participants. La mortalité maternelle aux États-Unis ne cesse d'augmenter et plus de 80 % des décès liés à la grossesse sont évitables, mais les signaux prédictifs vivent dans des parties complètement différentes du dossier. J'ai construit un serveur MCP qui les agrège, et un agent de triage qui lui délègue.