Pourquoi j'ai bâti un classificateur d'exoplanètes qui dit « Je ne sais pas »
Un classificateur XGBoost sur les données NASA Kepler, K2 et TESS, c'est un samedi après-midi. La partie intéressante, c'est tout ce qu'il y a autour : trois vraies classes (CONFIRMED, CANDIDATE, FALSE POSITIVE) plus un bac UNKNOWN d'abstention, téléversement de jeux de données, réentraînement dans le navigateur avec réglage des hyperparamètres, exploration 2D et vues 3D des systèmes.
La plupart des démos ML optimisent un seul chiffre sur un ensemble de test. La science ne fonctionne pas comme ça. Un scientifique préfère que vous signaliez le cas limite plutôt que de le mal classifier avec assurance. Alors NovaTrace livre une troisième classe (UNKNOWN) qui se déclenche quand le modèle n'est pas assez sûr pour se prononcer.
Pourquoi je l'ai construit
Je voyais toujours les classificateurs d'exoplanètes formulés comme un problème binaire de taux de réussite : planète ou non. Les vrais catalogues Kepler, K2 et TESS sont remplis de transits rasants, de binaires à éclipses qui imitent les planètes, et de variabilité stellaire qui déforme la courbe de lumière. Un scientifique qui regarde l'un de ces candidats ne veut pas un oui-ou-non forcé. La NASA elle-même utilise trois étiquettes (CONFIRMED, CANDIDATE, FALSE POSITIVE) précisément parce que le cas intermédiaire est réel. Il veut que le modèle respecte cette taxonomie et dise où sa décision est fragile. C'est cette lacune que je voulais combler.
La confiance comme citoyenne de première classe
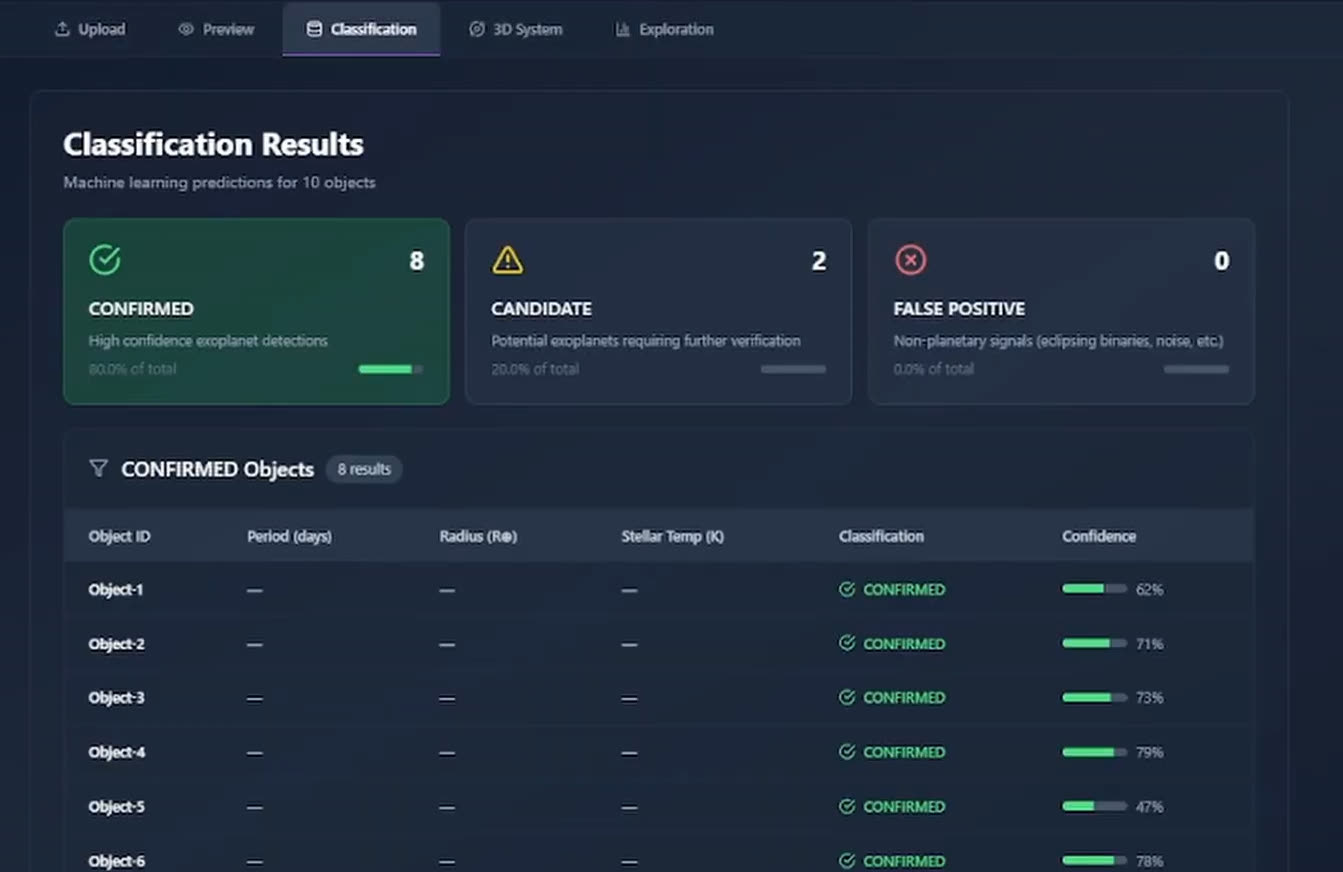
Le pipeline XGBoost émet une probabilité sur CONFIRMED, CANDIDATE et FALSE POSITIVE. Je seuille l'écart entre les deux premières : si le modèle hésite entre n'importe quelle paire, je ne fais pas semblant. Je pousse le candidat dans UNKNOWN et laisse l'utilisateur trancher. Ce bac d'abstention se superpose aux trois vraies étiquettes de la NASA, sans les remplacer, pour que la sortie reste compatible avec la façon dont les catalogues parlent réellement des candidats. C'est le seul moyen pour qu'un outil ML gagne sa place dans le flux d'un scientifique.
Ce que ça fait
- Classifie les candidats des catalogues Kepler, K2 et TESS de la NASA en CONFIRMED, CANDIDATE ou FALSE POSITIVE, avec UNKNOWN réservé aux cas que le modèle ne peut pas trancher avec confiance.
- Onglet Upload : téléversez un fichier Excel de candidats et passez-le dans le modèle entraîné, directement dans le navigateur.
- Onglet Data Exploration : nuages de points et histogrammes sur les prédictions et les caractéristiques astrophysiques, pour vérifier ce que le modèle lit vraiment.
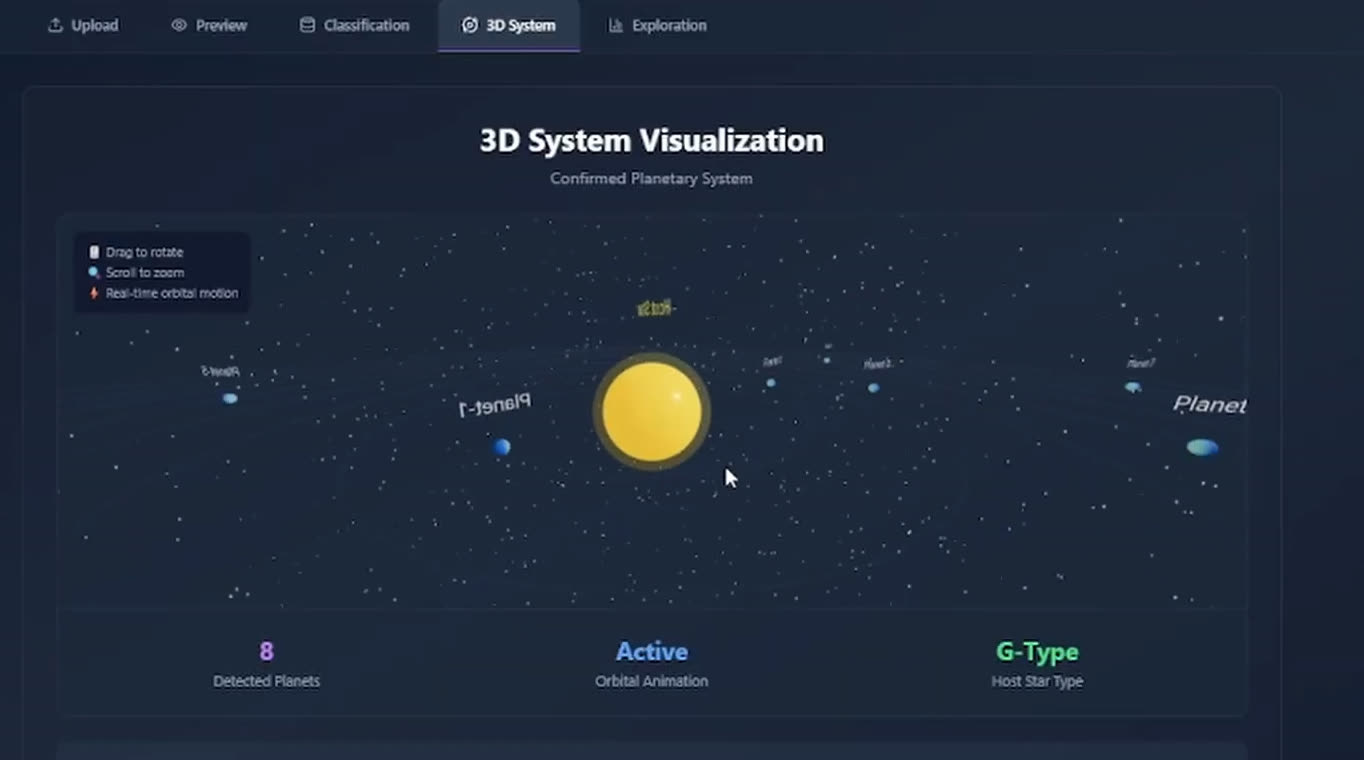
- Onglet 3D System Visualization : rend les planètes détectées, le type d'étoile hôte, l'architecture du système, la dynamique orbitale, la méthode de découverte et le statut d'habitabilité, avec rotation, zoom et mouvement orbital animé.
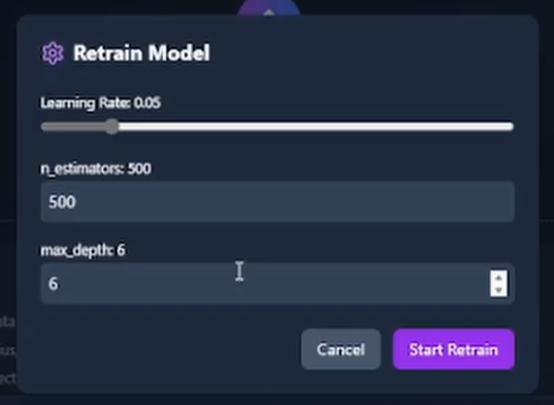
- Onglet Retrain Model : réajustez sur vos données téléversées et modifiez les hyperparamètres dans le navigateur, sans installation Python.
Comment je l'ai construit
Le classificateur est un modèle XGBoost entraîné sur les tables publiées d'objets d'intérêt Kepler, K2 et TESS, avec des caractéristiques de forme de transit et stellaires (période orbitale, profondeur de transit, durée, rayon stellaire, température effective). J'ai choisi XGBoost plutôt qu'un réseau profond exprès : les caractéristiques astrophysiques tabulaires sont précisément le régime où les arbres à gradient boosté battent encore les bases neuronales, et l'importance des caractéristiques sort du modèle gratuitement, ce dont j'avais besoin pour que l'onglet d'exploration visuelle ne soit pas décoratif.
L'interface est une application React + TypeScript + Tailwind avec Three.js pour la vue 3D du système et des graphiques SVG pour l'onglet d'exploration 2D. Le backend sert les prédictions et traite les requêtes de réentraînement en asynchrone pour que l'interface ne se bloque jamais pendant qu'un nouveau modèle s'ajuste sur les données téléversées.
Three.js comme outil de crédibilité
Les systèmes confirmés sont rendus en 3D temps réel : planètes détectées, type d'étoile hôte, architecture du système, dynamique orbitale, méthode de découverte qui a flaggé le système et statut d'habitabilité. Ce n'est pas de la déco, c'est un moyen pour l'utilisateur de vérifier la classification face à une géométrie étoile-planète qu'il connaît déjà. Si le modèle dit CONFIRMED pour un système dont la vue 3D semble fausse (orbite impossible, type d'étoile hôte incohérent), c'est une information.
Ce qui a été difficile
Choisir le seuil UNKNOWN était le vrai problème d'ingénierie. Trop serré et presque tout tombe dans UNKNOWN, ce qui est inutile. Trop lâche et la troisième classe ne se déclenche jamais, ce qui est malhonnête. Je l'ai calibré sur une portion mise de côté du catalogue pour que la zone UNKNOWN attrape les candidats que le modèle ne pouvait vraiment pas séparer, pas juste pour amortir la précision globale.
Permettre à l'utilisateur de réentraîner depuis le navigateur, sur ses propres données téléversées, avec des hyperparamètres ajustables, a ajouté une contrainte : la tâche d'entraînement devait être assez légère pour s'exécuter à la demande. J'ai plafonné l'ensemble de caractéristiques et la taille du sous-ensemble d'entraînement pour qu'un réentraînement finisse en secondes, pas en minutes, et le nouveau modèle est échangé de façon atomique sans perdre de requêtes. L'onglet Retrain Model reste un outil en direct au lieu d'un formulaire « revenez dans cinq minutes ».
Ce que j'ai appris
L'abstention calibrée est une fonctionnalité plus utile qu'un meilleur F1. Dès que j'ai ajouté UNKNOWN par-dessus les trois vraies classes de la NASA et que je l'ai jumelée aux nuages de points et histogrammes de l'onglet Data Exploration, l'outil a cessé de ressembler à une démo et a commencé à ressembler à quelque chose qu'un chercheur comme un passionné pourrait utiliser pour trier une liste de candidats.
La suite
- Ingérer les courbes de lumière brutes directement au lieu des seules tables de caractéristiques précalculées.
- Ajouter un graphique de calibration pour que les utilisateurs voient à quel point UNKNOWN suit l'incertitude réelle du modèle.
- Comparer XGBoost à un petit transformateur de base sur les mêmes caractéristiques comme vérification.
Transformer un téléphone en flux de réalisateur
La plupart des générateurs d'IA veulent un prompt par image. Shot Supervisor renverse la logique : un projet se décompose en scènes, les scènes en plans, et le contrôle déterministe en JSON de Bria FIBO maintient le langage visuel cohérent sur l'ensemble.

Pourquoi j'ai transformé une Steam Deck en console d'impression 3D
Lauréat du OpenAI Open Model Hackathon, parmi 8 652 participants : des modèles gpt-oss qui tournent hors ligne sur une Steam Deck, contrôle vocal via Vosk, visualisation STL en OpenGL, et OctoPi pour l'impression. De « imprime-moi un crochet pour mon bureau » à un crochet sur le plateau.