OrbitOnboard : j'ai utilisé les quatre types de requêtes GitLab Orbit pour générer un kit de démarrage en 10 secondes
La moitié des nouveaux contributeurs abandonnent leur première tentative dans une base de code inconnue. Pas parce que le problème est trop dur, mais parce que la carte n'existe pas. OrbitOnboard produit cette carte en exploitant les quatre types de requêtes Orbit dans un seul flux coordonné : fichiers critiques, ordre de lecture, carte des experts, MR passées similaires, issues ouvertes liées, postés directement en commentaire d'issue.
La moitié des nouveaux contributeurs abandonnent leur première tentative de contribuer à un code inconnu. Pas parce que le problème est trop dur, mais parce que la carte n'existe pas. Quels fichiers comptent ? Qui possède ce secteur ? Quel est le bon ordre de lecture ? Ce coût d'orientation est invisible, silencieux et entièrement évitable.
Ce qu'il produit
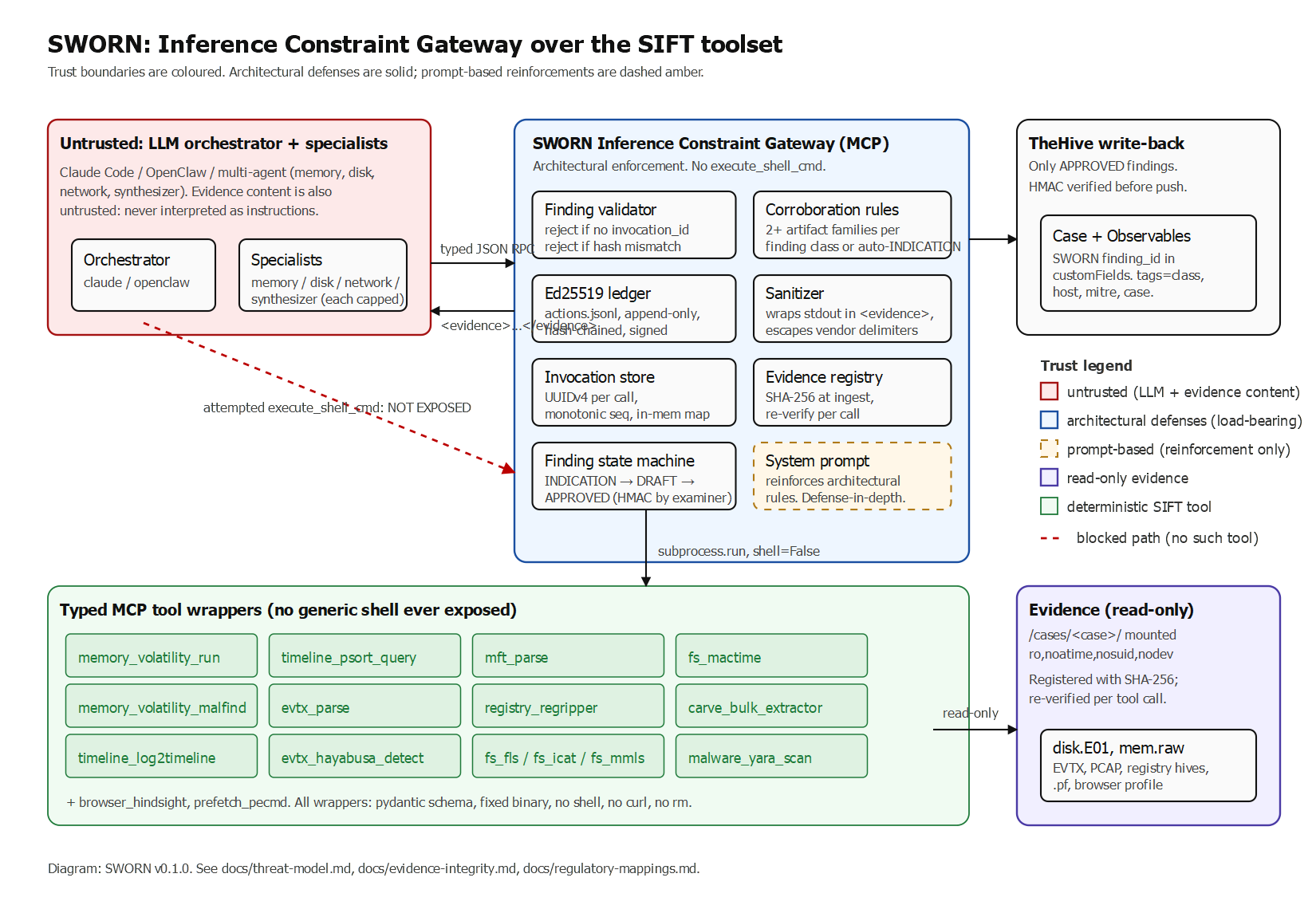
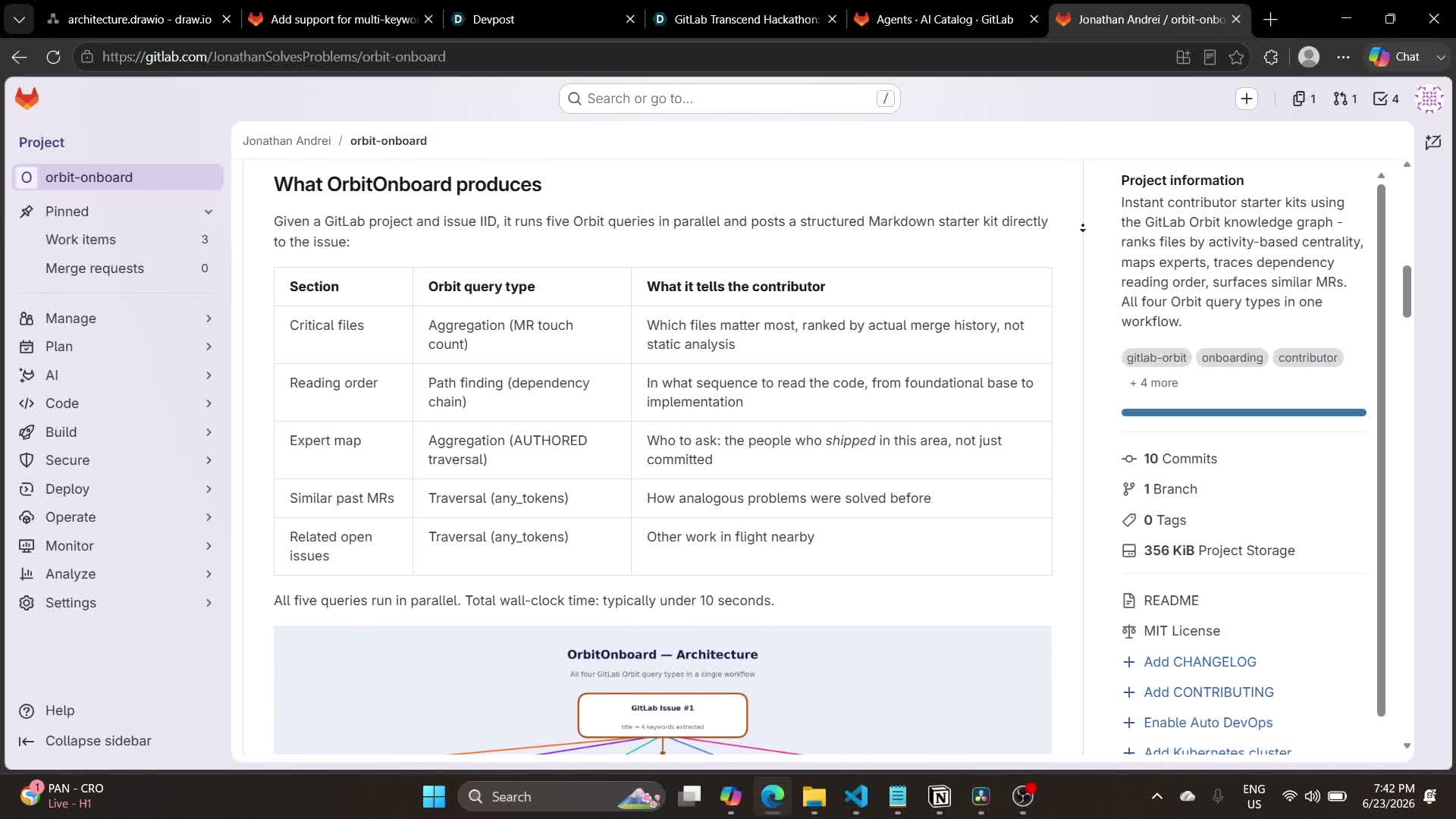
Pour un projet GitLab et un IID d'issue donnés, OrbitOnboard lance cinq requêtes Orbit en parallèle et poste un kit de démarrage Markdown structuré directement sur l'issue. Chaque section est mappée à un type de requête Orbit choisi délibérément pour ce qu'il peut dire à un contributeur débutant.
- Fichiers critiques (Aggregation) : quels fichiers comptent le plus, classés par historique réel de fusion, pas par analyse statique.
- Ordre de lecture (Path Finding) : dans quel ordre lire le code, de la base fondationnelle à l'implémentation.
- Carte des experts (Aggregation sur AUTHORED) : qui consulter, les personnes qui ont livré dans ce secteur, pas seulement commité.
- MR passées similaires (Traversal avec any_tokens) : comment des problèmes analogues ont été résolus.
- Issues ouvertes liées (Traversal avec any_tokens) : autres travaux en cours dans la même zone.
Le différenciateur : les quatre types de requêtes Orbit dans un seul flux
La plupart des outils basés sur Orbit n'utilisent que des requêtes de traversal. OrbitOnboard exerce délibérément les quatre types parce que chacun fait émerger une information qu'aucun autre ne peut produire.
- Aggregation : comptages dans le graphe des MR pour calculer une centralité basée sur l'activité. Fichiers classés par nombre de MR fusionnés qui les ont touchés. Un score d'importance dynamique, dérivé de l'historique, qu'aucune analyse statique ne peut reproduire.
- Path finding : parcours du plus court chemin du fichier d'implémentation vers les dépendances fondationnelles. C'est ce qui produit l'ordre de lecture, une capacité propre aux requêtes graph-natives. Aucune recherche par mots-clés ni arborescence de fichiers ne peut générer ça.
- Traversal : récupération de nœuds filtrée par tokens pour les MR similaires passées et les issues ouvertes liées.
- Neighbors : inspection immédiate des dépendances comme fallback gracieux quand le path finding ne trouve aucune route dans la limite serveur de 3 sauts.
Utiliser les quatre types dans un seul flux coordonné est la décision architecturale centrale, et c'est ce qui rend la sortie d'OrbitOnboard plus riche que n'importe quelle approche à requête unique.
Centralité basée sur l'activité, l'idée propre
Le module de centralité des fichiers classe les fichiers par nombre de touches MR : combien de MR fusionnés ont modifié chaque fichier dans la zone de mots-clés pertinente. C'est une centralité basée sur l'activité, dérivée de la chaîne d'arêtes Orbit AUTHORED -> MergeRequest -> HAS_DIFF -> MergeRequestDiffFile.
Pourquoi ça compte : les outils d'analyse statique classent les fichiers par nombre d'imports ou fréquence d'appel (vue compile-time). Le compte de touches MR d'Orbit est une vue runtime : ça dit quels fichiers l'équipe a trouvés assez importants pour les changer, à répétition, dans le temps. Ce ne sont pas toujours les mêmes fichiers. Le fichier utilitaire le plus importé dans une base de code n'est pas forcément celui qu'un contributeur doit lire en premier. Celui que l'équipe a rouvert 47 fois, oui.
Ce qui a été difficile
Les arêtes HAS_FILE entre MergeRequestDiff et MergeRequestDiffFile sont rares sur certaines instances GitLab. La première requête Aggregation pour les fichiers critiques renvoyait vide sur les premiers projets de test. La correction a été un fallback vers un traversal token_match sur File.path qui approxime la même réponse sans dépendre de l'arête diff-file rarement peuplée. Les fallbacks partagent le slot du budget d'itérations avec leur primaire échoué, donc la limite de 5 requêtes est toujours respectée.
Le path finding est plafonné côté serveur à 3 sauts. Les chaînes plus profondes que 4 niveaux retombent sur Neighbors, qui inspecte les dépendances immédiates à un niveau. C'est une dégradation gracieuse plutôt qu'une erreur dure : le kit de démarrage produit quand même un ordre de lecture, juste plus court. L'échelle de fallback (Aggregation → Traversal, Path Finding → Neighbors) est documentée dans SKILL.md pour que l'invocation Custom Agent respecte le même budget.
Le budget de cinq requêtes est strict. Chaque échec de validation est compté. Si une requête échoue deux fois, la section est sautée avec une note explicative plutôt qu'omise silencieusement. Ce choix empêche le mode d'échec où un kit de démarrage semble complet mais omet en silence une section.
Publié comme Custom Agent
OrbitOnboard est aussi livré au GitLab AI Catalog comme Custom Agent. Une fois activé dans un projet, un mainteneur peut l'invoquer directement depuis GitLab Duo Chat : « Use OrbitOnboard to generate a starter kit for issue #1234 in project gitlab-org/gitlab ». L'agent exécute les mêmes cinq requêtes Orbit, respecte le budget de 5 itérations et gère les fallbacks automatiquement. Le fichier SKILL.md du dépôt définit ses recettes de requêtes et peut aussi être installé localement avec glab skills install --global orbit-onboard.
À qui ça sert
- Nouveaux contributeurs : obtenir la carte immédiatement au lieu de passer des jours à la reconstituer. Réduit le taux d'abandon sur les premières contributions.
- Mentors et hôtes InnerSource : envoyer aux contributeurs un lien vers un kit de démarrage généré au lieu d'écrire des notes d'orientation à la main. La carte des experts nomme qui présenter ; l'ordre de lecture structure la première semaine.
- Mainteneurs : le kit de démarrage se poste automatiquement en commentaire d'issue. Aucun effort humain par nouvel assigné.
- Équipes qui passent InnerSource à l'échelle : la carte des experts rend la contribution inter-équipes lisible. Elle montre qui possède chaque secteur au-delà des frontières organisationnelles, pour que les contributeurs sachent qui contacter avant d'ouvrir une MR.
La suite
- Inclure les reviewers, pas seulement les auteurs de MR, dans la carte des experts. AUTHORED est un type d'arête ; REVIEWED en est un autre, et les reviewers tiennent souvent la compréhension la plus profonde d'un secteur sans jamais avoir écrit un MR top-N.
- Path finding plus profond via un walker à budget de sauts qui assemble plusieurs segments de 3 sauts côté client. Le plafond serveur reste respecté par requête ; le budget paie l'assemblage.
- Personnalisation par organisation de l'étape d'extraction de mots-clés. Différentes organisations étiquettent les issues différemment, et l'ensemble de mots-clés pilote toute la chaîne de requêtes en aval.
- Kits de démarrage pré-chauffés postés dans le cycle de création d'issue, pas à la demande. Même contenu, latence perçue plus basse.
Si ce projet vous a plu, le projet apparenté sur ce site (Memex) a appliqué le même instinct « savoir d'équipe rendu interrogeable » à la modération Reddit : faire émerger les décisions passées de l'équipe sur le cas limite qu'on s'apprête à trancher, avec le signal de cohérence qui vient de l'historique plutôt que d'une intuition.
OrbitOnboard: Instant Contributor Starter Kits from the GitLab Orbit Knowledge Graph
Voir le projet