FlakeWarden : 90,7 % de précision et 0 % de faux positifs côté sécurité sur le triage des tests instables, sur UiPath Maestro
Les tests instables sont le mode d'échec le plus corrosif en CI : un build rouge peut être une vraie régression ou juste du bruit, et les ingénieurs finissent par ignorer les builds rouges jusqu'à ce qu'un vrai bug parte en prod. FlakeWarden répond à la seule question qui compte (vrai défaut, instable, ou environnement) avec un scoreur d'instabilité déterministe pour les cas clairs et un classifieur UiPath Agent Builder ancré pour les cas ambigus, orchestré par Maestro avec un humain qui valide chaque changement. 90,7 % de précision sur un corpus de 150 cas, avec un taux de faux positifs côté sécurité de 0 % tenu par mécanisme.
Les tests instables sont le mode d'échec le plus corrosif en CI. Quand un build rouge peut être une vraie régression ou juste du bruit, un ingénieur soit brûle 15 à 45 minutes à trier chaque échec, soit, pire, finit par ignorer les builds rouges jusqu'à ce qu'une vraie régression parte en production. L'étude Google sur le test continu rapporte qu'environ 16 % de leurs tests présentaient un certain niveau d'instabilité et qu'environ 84 % des transitions « succès vers échec » venaient de tests instables. À titre de modèle : à un taux d'instabilité de 5 %, une suite de 2 000 tests produit environ 100 échecs parasites par exécution complète, soit, à 15 à 45 minutes de triage chacun, des dizaines d'heures-ingénieur par cycle.
FlakeWarden regarde l'historique d'exécution d'un test en échec et les preuves autour, puis répond à la seule question qui compte : est-ce un vrai défaut, un test instable, ou un problème d'environnement ? Il route ensuite chaque échec vers la bonne action, avec un humain à la barre de chaque changement.
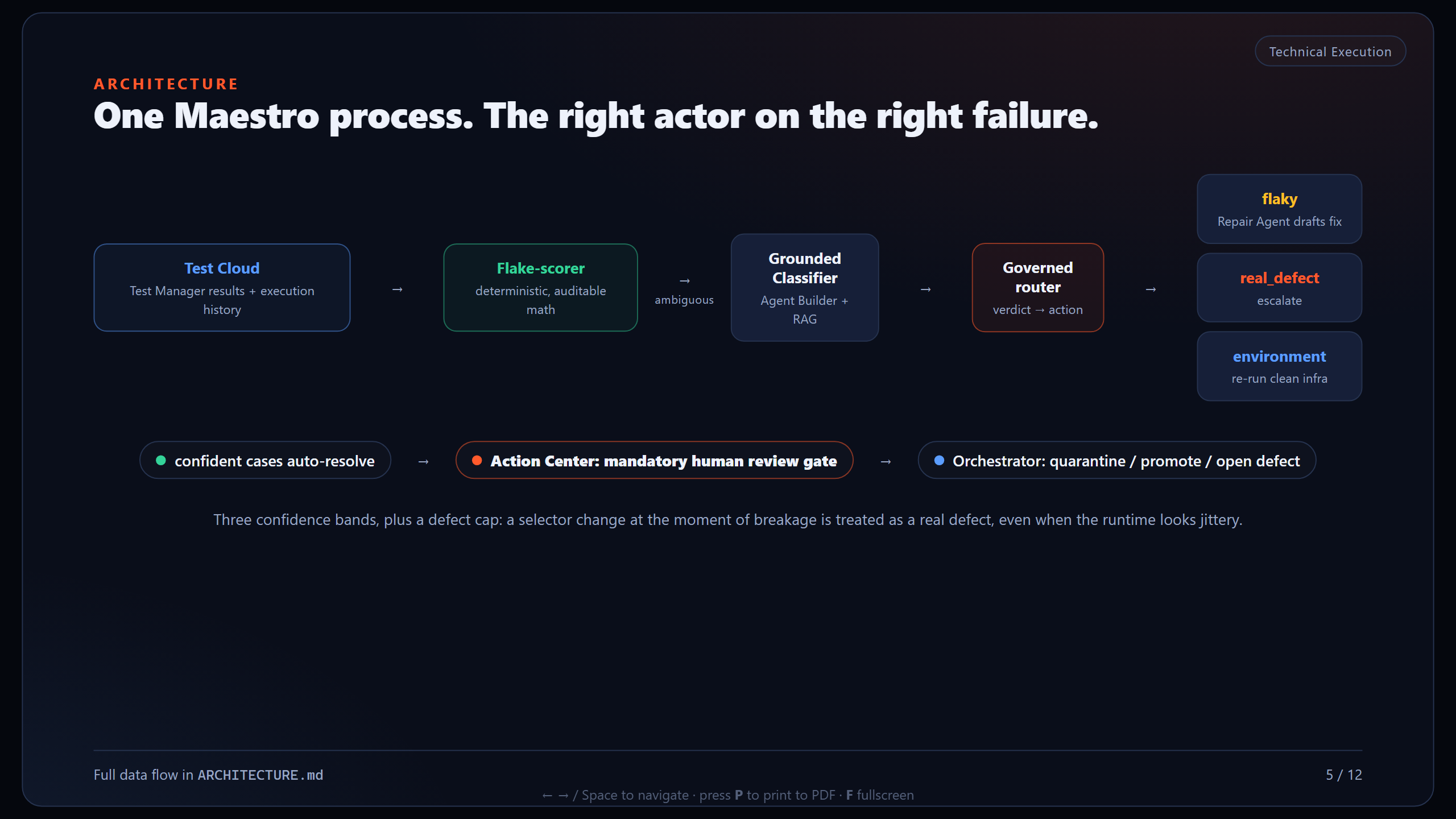
La frontière déterministe contre génératif
- Scoreur d'instabilité déterministe : statistiques auditables sur l'historique d'exécution. Gère les cas clairs et ne devine jamais. Environ un tiers des échecs (52 sur 150 dans l'éval) se résolvent ici sans appel de modèle.
- Classifieur Agent Builder ancré : RAG sur les stack traces, les diffs DOM, les messages de commit et les logs de runner. Raisonne uniquement sur les échecs ambigus et étiquette chacun en real_defect, flaky ou environment avec un raisonnement appuyé par les preuves.
- UiPath Maestro orchestre les deux plus un Repair Agent. Chaque correction, mise en quarantaine ou changement de baseline passe par une étape obligatoire de revue humaine dans Action Center, jamais une mutation autonome.
Le chiffre principal : taux de faux positifs côté sécurité de 0 %
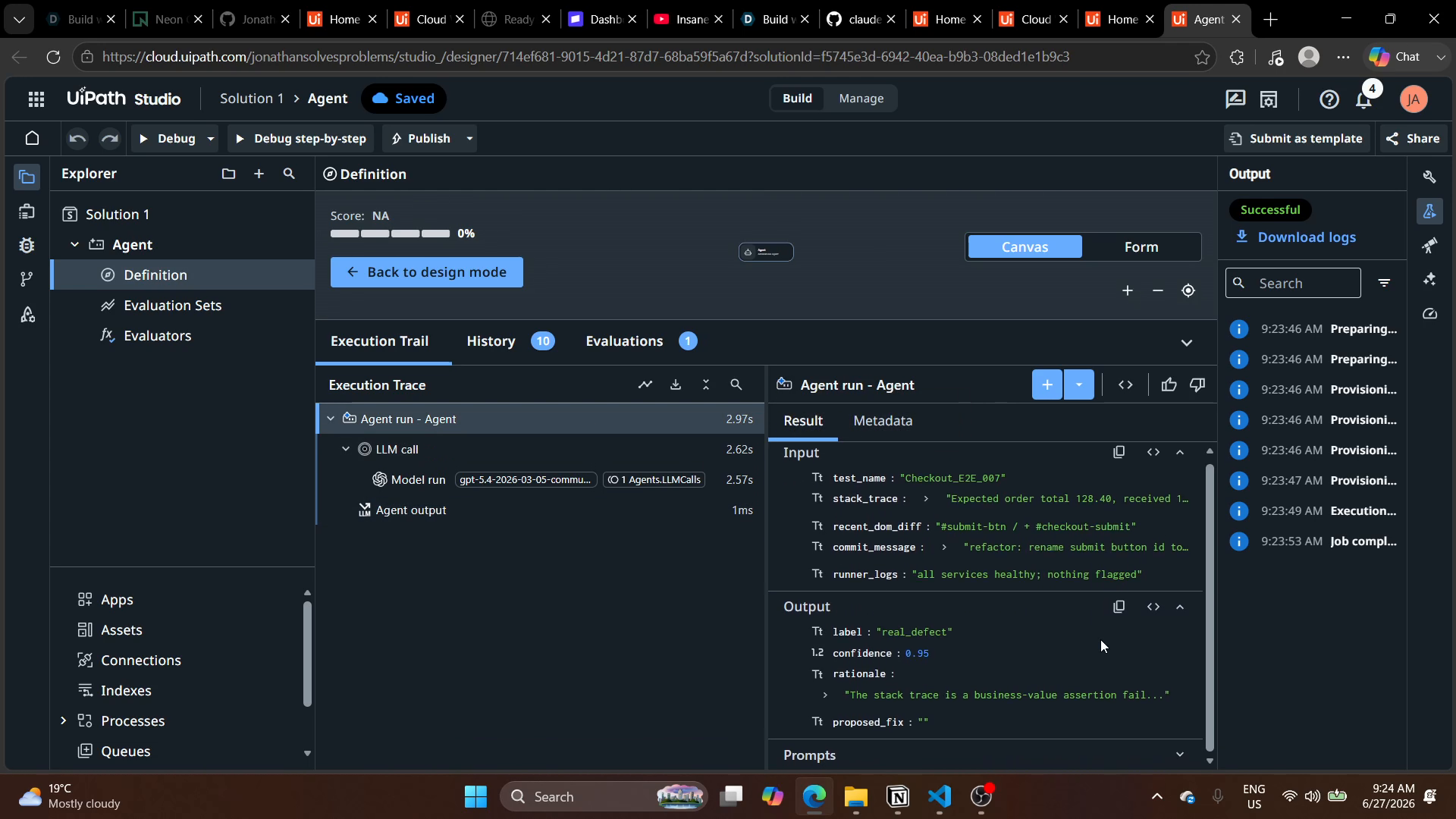
Mesuré sur un corpus étiqueté de 150 échecs : 90,7 % de précision globale et un taux de faux positifs côté sécurité de 0 %, ce qui signifie qu'aucune vraie régression n'est jamais cachée automatiquement comme instable ou environnement. Le 0 % est tenu par mécanisme, pas par chance : le scoreur n'auto-résout un défaut que sur empreinte de sélecteur positive ; un historique d'apparence instable mais avec un indice de régression est revérifié par le classifieur ; et le classifieur tranche en faveur de real_defect sur preuves partagées. eval/negative_control.py tourne comme garde-fou CI qui fait échouer le build si un défaut planté est jamais auto-soigné.
Les 12 % restants sont des erreurs côté bruit (un échec instable ou d'environnement escaladé comme défaut). Ça gaspille un peu de temps de triage mais ne cache rien, ce qui est la bonne queue de distribution pour un garde-fou CI.
Bâti de bout en bout avec Claude Code pilotant le CLI uip d'UiPath
Toute la solution (le scoreur déterministe, l'interface du classifieur, le harnais d'évaluation, l'orchestration Maestro, l'empaquetage et le déploiement) a été échafaudée et itérée avec Claude Code pilotant le CLI uip d'UiPath (UiPath for Coding Agents). La session a exécuté uip login, uip skills, uip tools install, uip agent deploy, et uip maestro bpmn registry/init/validate contre un tenant UiPath Labs en région EU, avec l'artefact de processus orchestrator (Solution.1.agent.Agent) déployé et le BPMN qui passe uip maestro bpmn validate.
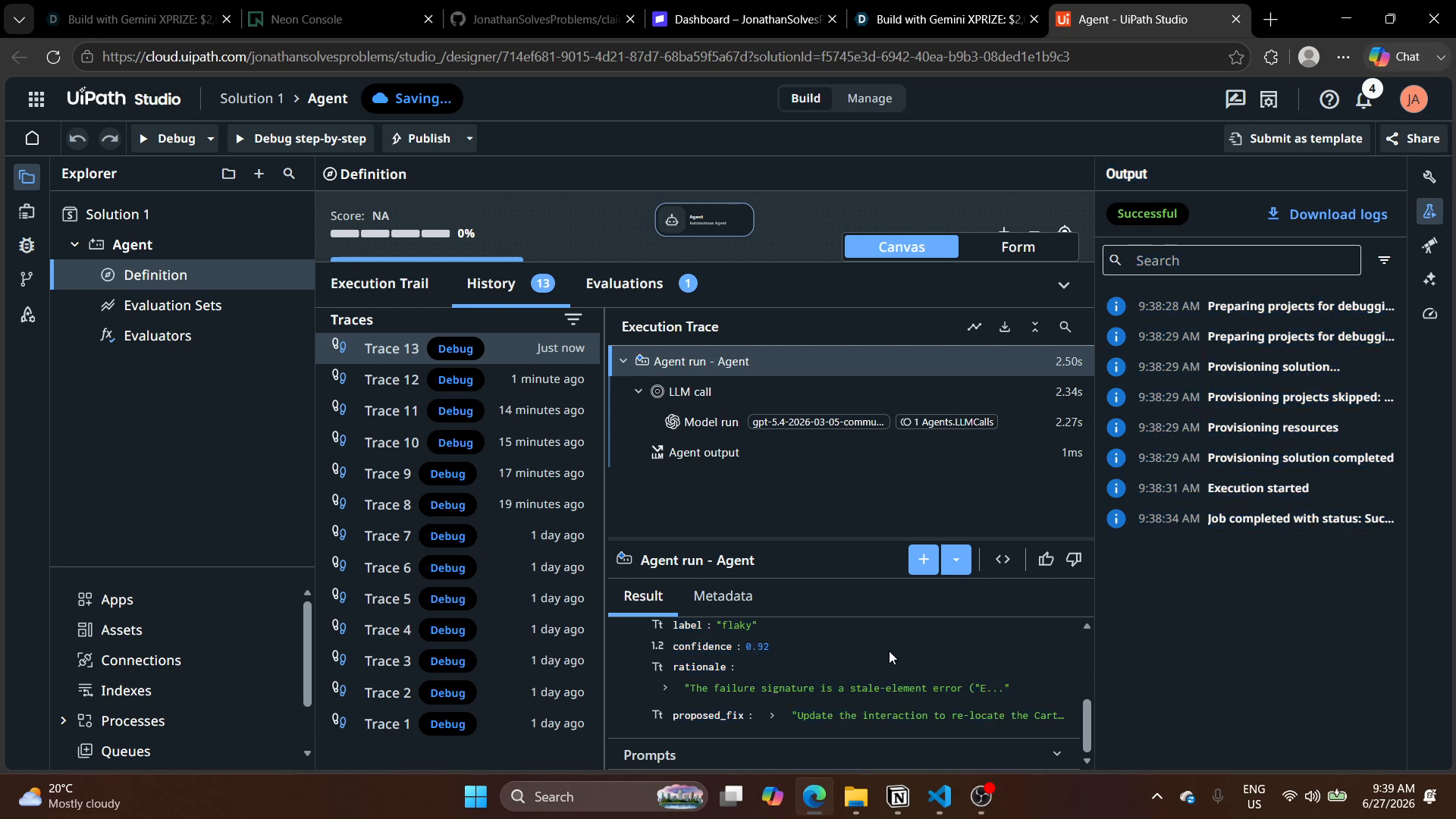
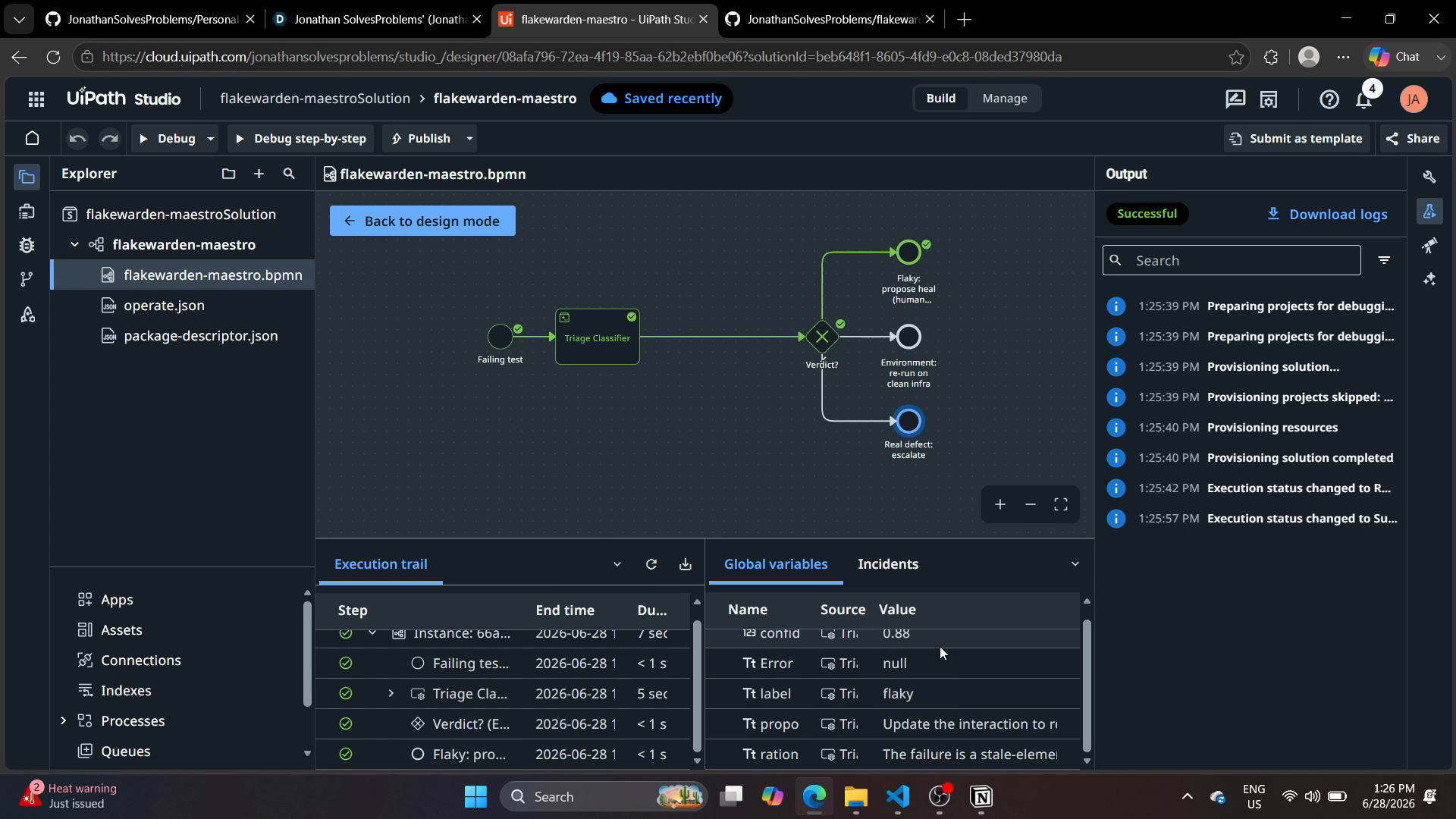
Orchestration Maestro (rédigée entièrement via le CLI)
Processus Maestro : Start → appel d'agent (Orchestrator.StartAgentJob sur le Triage Classifier déployé) → extraction du verdict → passerelle exclusive sur l'étiquette → trois branches routées : flaky → soin validé par humain, real_defect → escalade, environment → réessai. Pas de canevas graphique : chaque nœud, arête et entrée de registre a été rédigé comme sortie BPMN/JSON du CLI uip et validé localement avant déploiement.
Ce qui a été difficile
Une première version de l'évaluation était circulaire : le corpus encodait les signaux exacts que le modèle lisait. Je l'ai attrapé dans une auto-revue adverse et j'ai dé-truqué le corpus (signaux bruyants, vocabulaire découplé, vrais cas de conflit), pour re-mesurer à un honnête 90,7 % au lieu d'un chiffre tautologique. La leçon : le développement piloté par l'évaluation n'est honnête que si le jeu d'éval est découplé du modèle évalué.
Rendre le 0 % côté sécurité réel, pas conçu sur le papier : c'est désormais tenu par une garde de régression sur la bande instable plus un bris d'égalité vers real_defect, pour qu'un vrai bug ne puisse jamais être soigné en silence. eval/negative_control.py tourne comme garde-fou CI ; si un défaut planté est jamais routé hors de la branche défaut, le build échoue.
Courbe d'apprentissage de la plateforme UiPath : la liaison des arguments de prompt utilise le sélecteur @, pas du texte tapé {{ }}, et l'évaluateur d'agent intégré ne pouvait pas router son modèle dans le tenant EU (HTTP 417 résidence de données). L'agent lui-même tourne très bien ; le routage de modèle de l'évaluateur est une vraie lacune que je remonte comme retour produit.
Limites honnêtes
Le corpus de 150 cas est synthétique mais adverse : un builder solo ne peut pas livrer l'historique CI d'une vraie entreprise. La production demande de connecter l'API de résultats Test Manager en direct à la place du corpus amorcé, puis de mener une étude prospective en mode shadow pour rapporter une précision réelle contre un jeu étiqueté étalon. L'architecture, les garde-fous de gouvernance et la méthodologie d'éval ont la forme d'une production ; c'est la donnée qui manque. Le 0 % côté sécurité de la une dépend aussi du mécanisme qui le tient ; sur une distribution de preuves différente, ce mécanisme demande une re-validation, pas une réutilisation aveugle.
FlakeWarden: Agentic Flaky-Test Triage With a 0% Safety False-Positive Rate, on UiPath Maestro
Voir le projet