FlakeWarden: 90.7% Accuracy and a 0% Safety False-Positive Rate on Flaky-Test Triage, on UiPath Maestro
Flaky tests are the most corrosive failure mode in CI: a red build might be a real regression or just noise, and engineers eventually start ignoring red builds until a real bug ships. FlakeWarden answers the only question that matters (real defect, flaky, or environment) with a deterministic flake-scorer for the clear cases and a grounded UiPath Agent Builder classifier for the ambiguous ones, orchestrated through Maestro with a human approving every change. 90.7% accuracy on a 150-case corpus, with 0% safety false-positive rate enforced by mechanism.
Flaky tests are the most corrosive failure mode in CI. When a red build might be a real regression or just noise, an engineer either burns 15 to 45 minutes triaging every failure or, worse, starts ignoring red builds until a genuine regression ships. Google's continuous-testing study reported that about 16% of their tests had some flakiness and that about 84% of pass-to-fail transitions came from flaky tests. As an illustrative model: at a 5% flake rate a 2,000-test suite produces around 100 spurious failures per full run, which at 15 to 45 minutes of triage each is tens of engineer-hours per cycle.
FlakeWarden looks at a failing test's execution history and the surrounding evidence and answers the only question that matters: is this a real defect, a flaky test, or an environment problem? It then routes each failure to the right action, with a human in charge of every change.
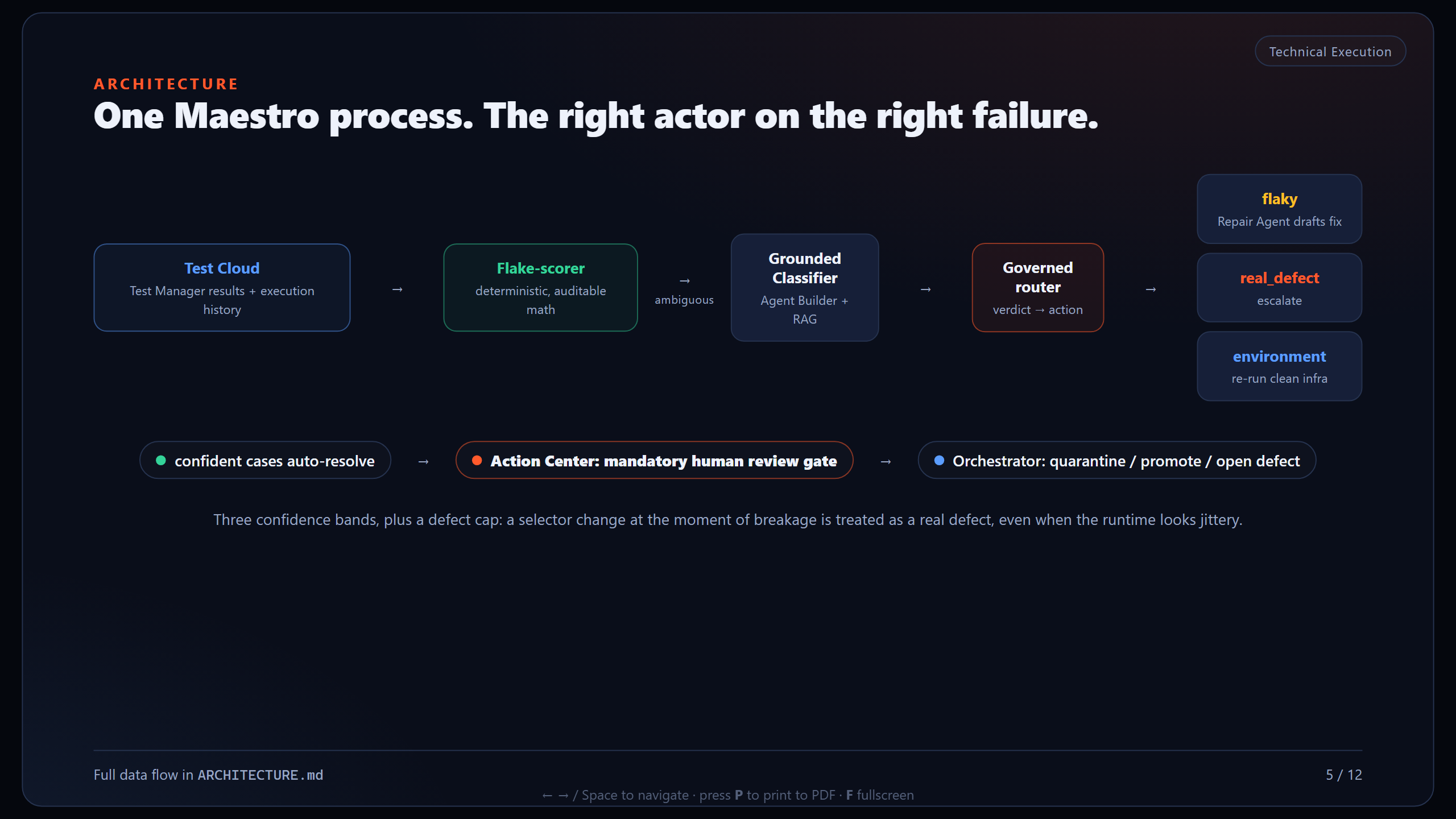
The deterministic-vs-generative boundary
- Deterministic flake-scorer: auditable statistics over run history. Handles the clear cases and never guesses. About a third of failures (52 of 150 in the eval) resolve here with no model call.
- Grounded Agent Builder classifier: RAG over stack traces, DOM diffs, commit messages, and runner logs. Reasons over only the ambiguous failures and labels each one real_defect, flaky, or environment with evidence-cited reasoning.
- UiPath Maestro orchestrates the two plus a Repair Agent. Every fix, quarantine, or baseline change passes through a mandatory Action Center human-review gate, never an autonomous mutation.
The headline number: 0% safety false-positive rate
Measured on a 150-failure labeled corpus: 90.7% overall accuracy and a 0% safety-direction false-positive rate, meaning no real regression is ever auto-hidden as flaky or environment. The 0% rate is enforced by mechanism, not luck: the scorer only auto-resolves a defect on a positive selector fingerprint; a flaky-looking history with any regression hint is double-checked by the classifier; and the classifier tie-breaks toward real_defect on split evidence. eval/negative_control.py runs as a CI gate that fails the build if a planted defect is ever auto-healed.
The remaining 12% is noise-direction error (a flaky or environment failure escalated as a defect). That wastes a little triage time but hides nothing, which is the right tail to land on for a CI guardrail.
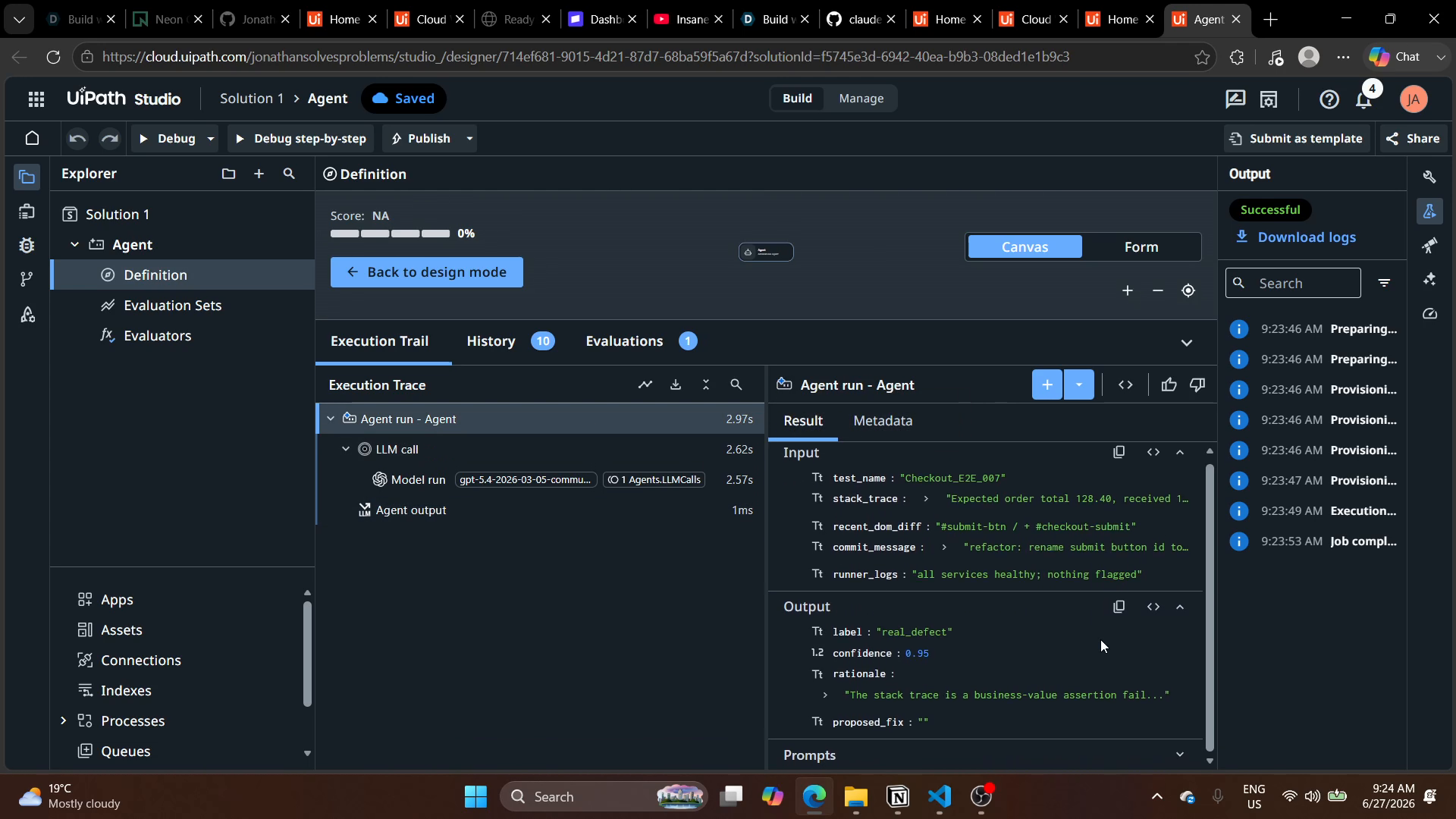
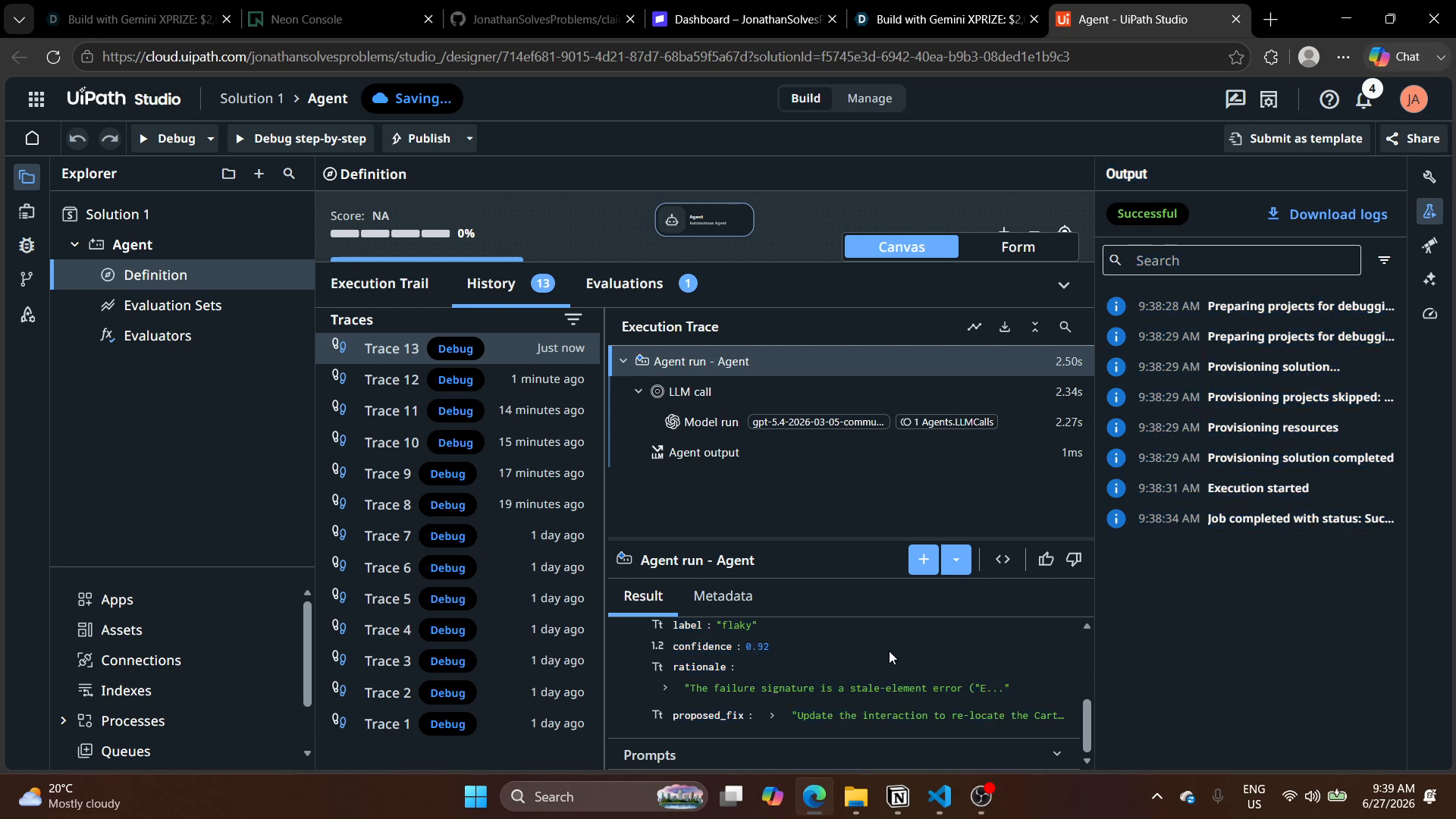
Built end-to-end with Claude Code driving the UiPath uip CLI
The entire solution (the deterministic scorer, the classifier interface, the eval harness, the Maestro orchestration, packaging, and deployment) was scaffolded and iterated using Claude Code driving the UiPath uip CLI (UiPath for Coding Agents). The session ran uip login, uip skills, uip tools install, uip agent deploy, and uip maestro bpmn registry/init/validate against an EU UiPath Labs tenant, with the orchestrator process artifact (Solution.1.agent.Agent) deployed and the BPMN passing uip maestro bpmn validate.
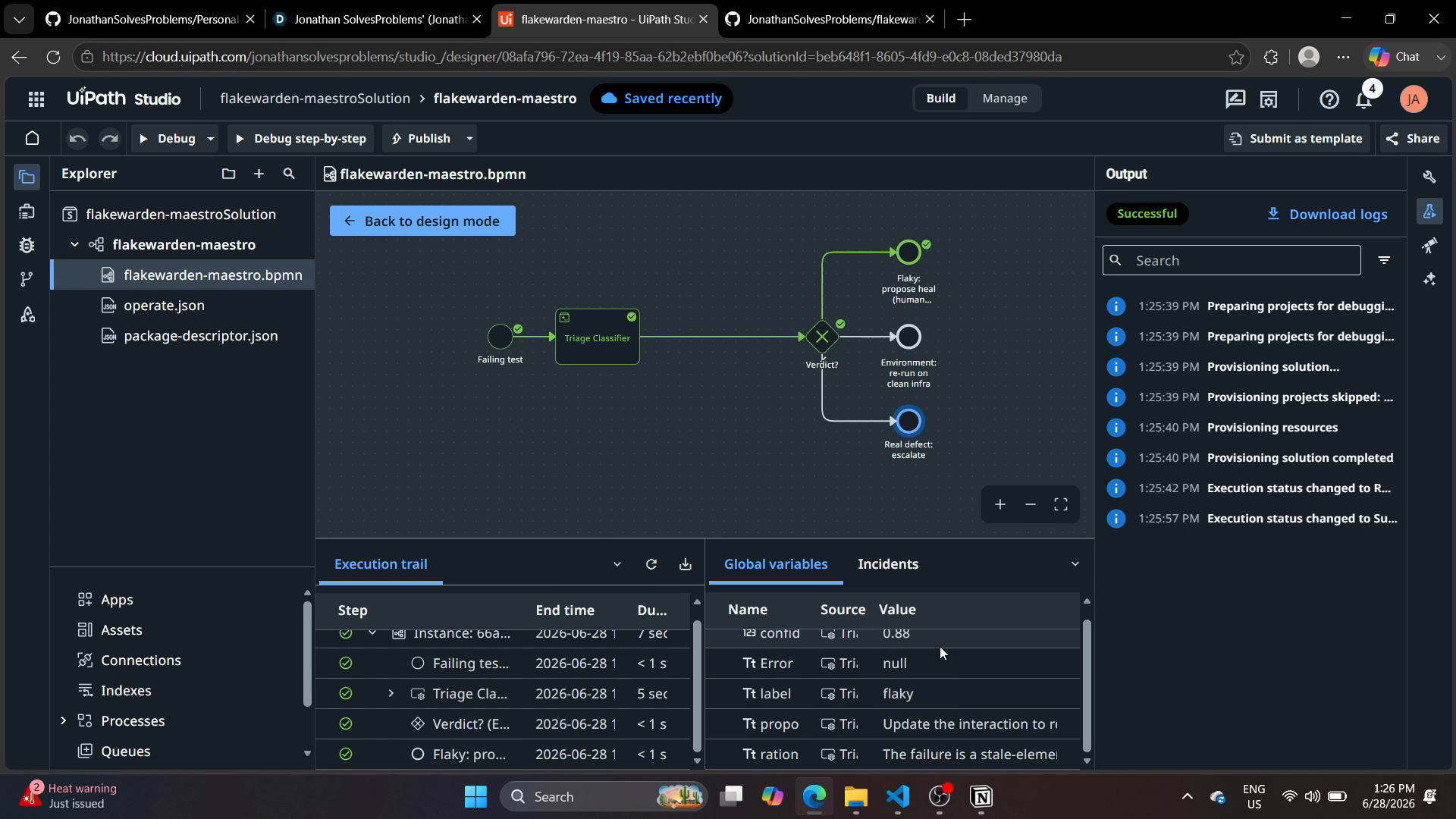
Maestro orchestration (authored entirely through the CLI)
Maestro process: Start → agent call (Orchestrator.StartAgentJob on the deployed Triage Classifier) → verdict extraction → exclusive gateway on the label → three routed branches: flaky → human-gated heal, real_defect → escalate, environment → re-run. No graphical canvas: every node, edge, and registry entry was authored as the uip CLI's BPMN/JSON output and validated locally before deploy.
What was hard
An early version of the evaluation was circular: the corpus encoded the exact signals the model read back. I caught it in an adversarial self-review and de-rigged the corpus (noisy signals, decoupled vocabulary, genuine conflict cases), re-measuring at an honest 90.7% instead of a tautological number. The lesson: evaluation-driven development is only honest if the eval set is decoupled from the model under test.
Making the 0% safety rate real, not designed: it is now enforced by a flaky-band regression guard plus a tie-break toward real_defect, so a real bug can never be silently healed. eval/negative_control.py runs as a CI gate; if a planted defect ever gets routed away from the defect branch, the build fails.
UiPath platform learning curve: binding prompt arguments uses the @ picker, not {{ }} typed text, and the in-product agent evaluator could not route its model in the EU tenant (HTTP 417 data-residency). The agent itself runs fine; the evaluator model routing is a real gap I am submitting as product feedback.
Honest limitations
The 150-case corpus is synthetic-but-adversarial: a solo builder cannot ship a real enterprise's CI history. Production requires connecting the live Test Manager results API in place of the seeded corpus, then running a shadow-mode prospective study to report real-world accuracy against a gold-standard labeled set. The architecture, governance gates, and eval methodology are production-shaped; the data is the gap. The headline 0% safety rate also stands or falls with the mechanism that enforces it; on a different evidence distribution that mechanism needs re-validation, not blind reuse.
FlakeWarden: Agentic Flaky-Test Triage With a 0% Safety False-Positive Rate, on UiPath Maestro
View the project